Schon seit einigen Jahren folge ich Jeremy Howards Arbeit rund um fast.ai. fast.ai’s Slogan “Making neural nets uncool again”, klingt vielleicht erstmal komisch. Im Kern ist er so zu verstehen, dass fast.ai die Nutzung von Deep Learning so einfach und zugänglich machen soll für jeden – und damit sind ganz ausdrücklich nicht nur Machine Learning Experten gemeint, sondern auch Programmierer jeder Sorte und solche, die es werden wollen, dass Neural Nets aufhören, ein Big Deal zu sein und einfach ein weiteres nützliches Tool im Arsenal von Menschen sind, die etwas Tolles bauen wollen.
Bislang habe ich fast.ai nur privat verwendet und professionell mit Tensorflow gearbeitet. Ich will den gerade wieder neu begonnenen Kurs von Jeremy Howard “Practical Deep Learning for Coders (fast.ai)” dieses Mal von Anfang an mitmachen und sowohl die Inhalte als auch meine Arbeit etwas dokumentieren, damit auch ihr Leser etwas (auf Deutsch) davon habt.
Howard empfiehlt, möglichst früh praktisch aktiv zu werden:
- z.B. eigene Modelle vs ausuferndes Lernen der Theorie
- nicht nur lesen, sondern auch Bloggen etc.
Auch finde ich es gut, das Gelernte und Erarbeitete überprüfbar hier im Netz zu haben für mich und andere, um den Lernloop am Laufen zu halten 🙂
Hier nun meine Wiedergabe der Lektion Null seines Kurses “Deep Learning für Coder” aus dem Jahr 2021. Hier direkt das Video, darunter der Text, für die von euch, die lieber lesen.

Lesson “0”: Practical Deep Learning for Coders (fast.ai)
Link zu YouTube (no cookies Version)
Lektion 0 How to fast.ai
Zu Lektion 1: Optionaler Kurs, der erklärt wie man das meiste aus dem Kurs herausholen kann und wie man es schafft, bis zum Ende am Ball zu bleiben. Zudem zeigt er in diesem Kurs wie man praktisch loslegen kann (mit Google Collab und Amazon AWS EC2) (0:07)
Viele haben Jeremy, nachdem sie den Kurs gemacht haben, gesagt, erst “jetzt” verstanden zu haben, was sie hätten anders machen sollen. Und dann den Kurs ein zweites Mal gemacht. Um das zu ersparen hat Jeremy seine Ideen und Kommentare und Best Practices anderer gesammelt, die er in dieser Lektion Null erklärt.
Was Kursabsolventen machen und wie man zu einem Kursabsolventen wird. (1:14)
Tausende Leute haben den Kurs abgeschlossen und haben Startups gegründet, wissenschaftliche Veröffentlichungen geschrieben oder in dem Unternehmen, für das sie arbeiten neue Produkte gebaut. Der Kurs hat sich praktisch gut bewährt. Aber: Viele schließen den Kurs auch nie ab.
Wenn “vom Kurs” die Rede ist, geht es entweder um die Video-Serie (hier: https://course.fast.ai/) oder um das Buch: Deep Learning for Coders with fastai and PyTorch: AI Applications Without a PhD
Jeremy betont, dass er an dem Buch so gut wie nichts verdient und man es daher nur kaufen soll, wenn man besser mit Papier klar kommt. Man kann das Buch auch völlig umsonst hier lesen: https://github.com/fastai/fastbook
Das Buch ist in Form eines Jupyter Notebooks geschrieben. In diesem Kurs geht es um die erste Hälfte des Buchs. Im zweiten Teil des Kurses geht es um die zweite Hälfte.
Jeremys Hauptbotschaft: Schließe den Kurs ab (oder lese die erste Hälfte des Buchs)! (3:21)
Daher: Nimm dir einen Tag, an dem du den Kurs schaust, einen Tag an dem du liest und einen Tag an dem du die Hausaufgaben erledigst. Versetze dich durch den Plan in die Lage, den Kurs regelmäßig zu bearbeiten und so abzuschließen.
Erzähle es deinen Freunden oder deinem/r Partner/in, um sozialen Druck zu erzeugen.
Schließe den Kurs und EIN Projekt ab. (4:27)
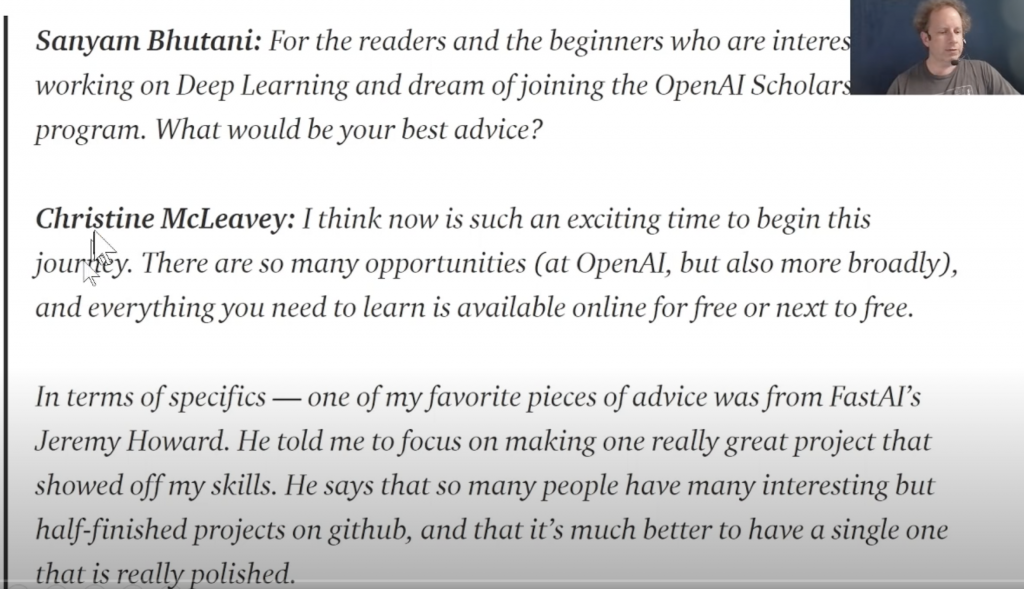
Hier dazu ein Zitat aus einem Podcast mit einer Alumna des Kurses, die jetzt als Forscherin bei OpenAI arbeitet (eine der führenden Forschungsorganisationen im Themenbereich weltweit). Sie hat ein Model zur Erstellung von Musik geschrieben.
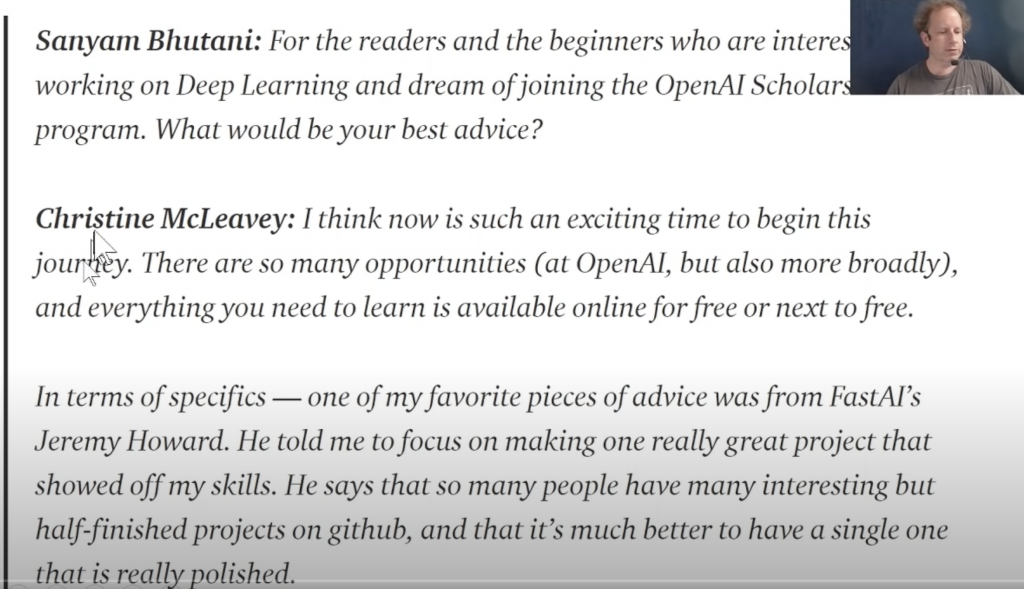
Freie, sinngemäße Übersetzung:
Sangam Bhutan: Was ist deine Empfehlung für Neulinge mit dem Traum Deep Learning Wissenschaftler zu werden:
Christine McLeavey: … einer meiner Lieblingsratschläge stammt von FastAI’s Jeremy Howard. Er meint: Konzentriere dich darauf, EIN Projekt wirklich gut zu machen, und damit deine Fähigkeiten zu zeigen. Es gibt so viele interessante, aber nur halbfertige Projekte auf GitHub. Es ist besser eins zu halben, das wirklich gut ist.
In Kürze: Fokussiere dich auf ein Projekt, poliere es und mache es fertig.
Christine McLeavey hat dieser Fokus geholfen, ein Modell zu erstellen, dass Musik geschrieben hat, die vom BBC Orchester gespielt wurde und ihr u.a. half, den angesehenen Job bei OpenAI zu bekommen.
Projekt auswählen (5:49)
Es muss nichts sein, dass noch nie jemand vorher gemacht hat. Es reicht völlig, wenn man etwas interessant findet und denkt: “Wäre es nicht cool, wenn auch ich das bauen könnte”. Es muss auch nichts sein, dass einen riesigen gesellschaftlichen Mehrwert hat. Howard nennt das Beispiel eines Vetter/Basen-Erkenners. Die Frau eines Absolventen hatte 14 Vetter/Basen. Also baute er ein Modell, dem man ein Bild geben konnte und das im Abschluss erkennen konnte, welcher Vetter oder welche Base auf dem Bild abgebildet war.
Ein anders Projekt des ersten Kurses, den Howard hielt, erstellte das Modell für die amerikanische TV-Show “Hot Dog or Not Hot Dog”. Und dieses Modell tat nichts weiter, als zu erkennen, ob ein Bild einen Hot Dog zeigt oder nicht. Es kann aber auch etwas ernsthaftes sein, wie das Lösen eines medizinischen Problems.
Hartnäckigkeit (6:52)

Freie Übersetzung: Die einzige konsistente Eigenschaft, die fast.ai Studenten, die zu Weltklassepraktikern wurden, gemeinsam haben ist Hartnäckigkeit.
Howard sagt: Hartnäckigkeit ist keine unverändertere Charaktereigenschaft, sondern man kann sich entscheiden, hartnäckig zu sein.
Es geht nicht darum Probleme (wie eine globale Pandemie oder persönliche Rückschläge) zu ignorieren, es geht darum, den Faden irgendwann wieder aufzugreifen – und sei es, indem man die E-Mail zu schreibt, die man seit einem Jahr aufgeschoben hat.
Zum Buch Meta Learning – Buch von Radek Osmulski (fast.ai Absolventen) darüber wie man zu einem erfolgreicher Deep Learning Praktiker wird (08:26)
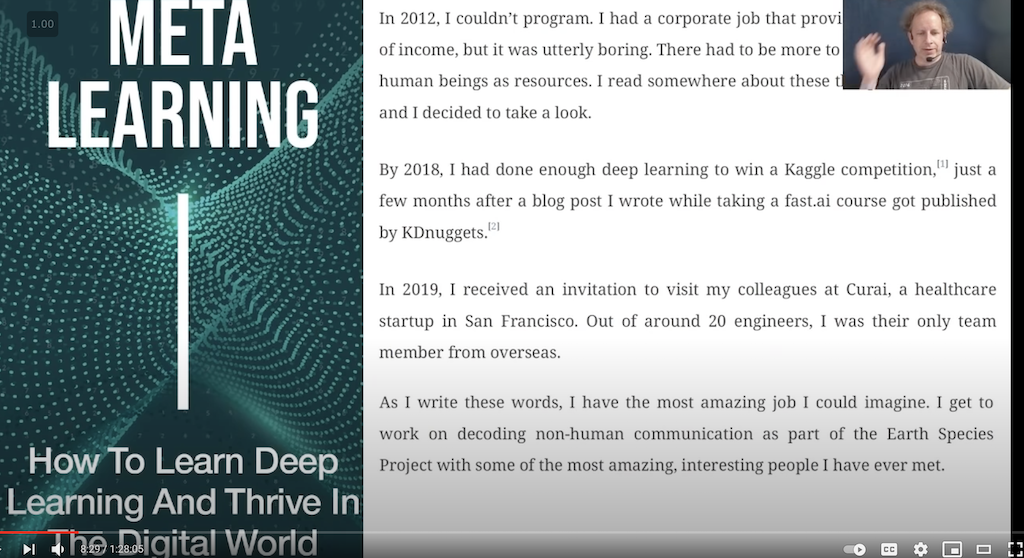
Howard empfiehlt, es zu lesen. Radek konnte noch vor ein paar Jahren nicht programmieren, hatte keinen Schulabschluss, einen Job, den er langweilig fand. Er hat sich in den Kopf gesetzt, Deep Learning zu lernen und versagte zuerst wieder und wieder. Weil er aber hartnäckig war, versuchte er es immer weiter. Schließlich fand er heraus, wie er es lernen konnte: fast.ai und Philosophie zu lernen.
Er ist jetzt ein Kaggle Wettbewerb Gewinner 2019. 2019 war er der einzige Mitarbeiter aus Übersee beim Startup curai (ein Medizinstartup in San Francisco) und arbeitet jetzt für eine Non-Profit-Organisation, die es sich zur Aufgabe gemacht hat, Tiersprachen zu übersetzen.
Howard findet, er ist ein gutes Vorbild, wie man durch Trial und Error zum Erfolg kommt.
Hier noch ein Twitterzitat von Radek:
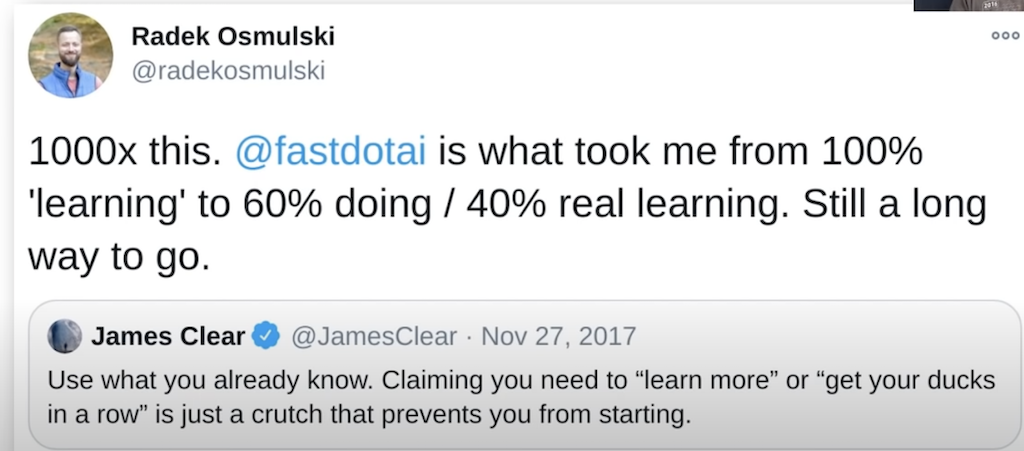
Was wir von nicht erfolgreichen Deep Learning Lernenden immer wieder hören (10:33)
Am häufigsten ist die Tendenz, sich sehr lange darauf vozubereiten, Deep Learning oder Projekte zu machen: Sie lernen Lineare Algebra, sie lernen Analysis, danach lernen sie C++ usw. – und fangen aber nie – oder erst sehr spät praktisch an.
Die FastAI Philosophie ist: Fange in der ersten Woche an, ein Modell zu bauen!
Das heißt nicht, dass man nicht auch die Theorie lernen wird. Aber das kommt erst später, Schritt für Schritt, wenn man den Kontext hat.
Wenn man Kurs 1 und Kurs 2 abgeschlossen hat, wird man praktisch den ganzen fast.ai Code selbst neu implementiert haben und dabei alles kennengelernt haben, Batch Normalization, Back Propagation etc. – man wird alles tun, aber im Kontext einer konkreten Aufgabe – nicht vor der Praxis.
Das wichtigste ist, Code schreiben, Experimente machen und Modelle trainieren.
Wenn man noch gar nicht Coden kann: CS50 und Missing Semester. (12:25)

Wenn man noch nicht gut im Coden ist: Das ist kein Problem, sondern eine Gelegenheit, denn mit fast.ai habt ihr einen guten Anlass, Programmieren für etwas zu lernen, das großen Spaß macht.
Viele sind gute Programmierer durch den Kurs geworden! Viele Konzepte werden in diesem Rahmen erklärt: Python List comprehension, objektorientiertes und funktionales Programmieren, GPU-Beschleunigung usw.
Sofern ihr ein Stück Code, Befehle seht, die euch nichts sagen, ist das eine Gelegenheit, eine Pause zu machen und sich etwas Zeit zu nehmen, um zu verstehen, was der Code macht.
Wer ganz anfängt, dem sei – so Radek und auch Howard – der Kurs: CS50 der Harvard Universität empfohlen. Er kostet nichts und steht hier online (Englisch) zur Verfügung:
Radek 4-Beiniger Tisch (14:02)
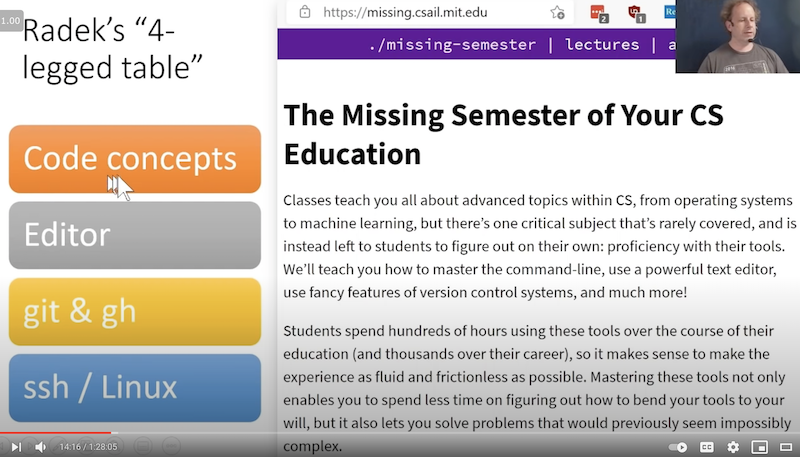
Radek spricht vom 4-beinigen Tisch. Die Beine sind:
- Code-Konzepte
- Editor (Jupyter Notebook)
- git & gh
- ssh / Linux
Dazu wird der von MIT-Studenten erstellte Kurs “missing semester” empfohlen, da von ihnen viele Technologien direkt zu Beginn erwartet, aber nicht gelehrt wurden. Ihr findet ihn (kostenlos, Englisch) hier: https://missing.csail.mit.edu/
Auch hier gilt wieder: Am wichtigsten ist es, diese Werkzeuge praktisch anzuwenden!
Kommunikation und Teilen der eigenen Arbeit (15:30)

Bloggen, Tweeten, Forum-Nachrichten. Radek und Howard sagen: Ein wichtiger Teil des Lernprozesses ist es, so früh wie möglich eigene Fortschritte, Projekte und das eigene Verständnis zu teilen.
Keine Scham! Auch als Anfänger seid ihr bereits die besten Experten für die, die noch nichts wissen – wie ihr vor 6 Monaten! Außerdem seid ihr wiederum in eurer Branche vermutlich einer der wenigen, der sich auch mit dem Thema Deep Learning schon beschäftigt hat und daher sind eure Kommentare wertvoll.
Notizen zu machen hilft eurem Lernverständnis und es hilft euch, nach und nach euer Portfolio aufzubauen.
Wie macht man eine fast.ai Lektion? (17:25)

1. Lektion anschauen: Eine fast.ai Lektion besteht aus einem Kapitel im Buch oder einem Video des Kurses (oder beidem).
2. Notebook ausführe & experimentieren: Als nächstes führt man das Jupyter Notebook aus. Dabei sollte man ruhig experimentieren. Wenn ihr euch fragt, was eine Code-Zeile tut: Entfernt sie und guckt, was dann passiert oder ändert etwas daran. Probiert andere Inputdaten aus.
Mit jedem Experiment füttert ihr euer Gehirn, sodass darin selbst Deep Learning durch Input Output stattfinden kann.
3. Ergebnisse reproduzieren: Ein nächster Schritt ist das Notebook selbst neu zu schreiben.
Also, schreibt in einer leeren Version des Notebooks selbst Teile Schritt für Schritt neu. Wenn nötig, mit der Referenz zur Lösung, aber wo möglich selbstständig.
4. Mit anderen Daten wiederholen: Schließlich soll man versuchen die Pipelines oder Modelle im Notebook mit anderen Daten, die man selbst gesammelt oder im Internet heruntergeladen hat, neu zu auszuführen.
Dieser Ablauf kann ggf. dazu führen, dass man den Kurs mehrere Male durchgeht. Man soll und muss sich nicht damit frustrieren, alle diese Schritte beim ersten Durchlauf zu können. Arbeite einfach, so weit wie du kommst. Gehe ggf. zu einem älteren Notebook zurück und versuche dort einen neuen Schritt.
Wie der Kurs aussieht (20:37)
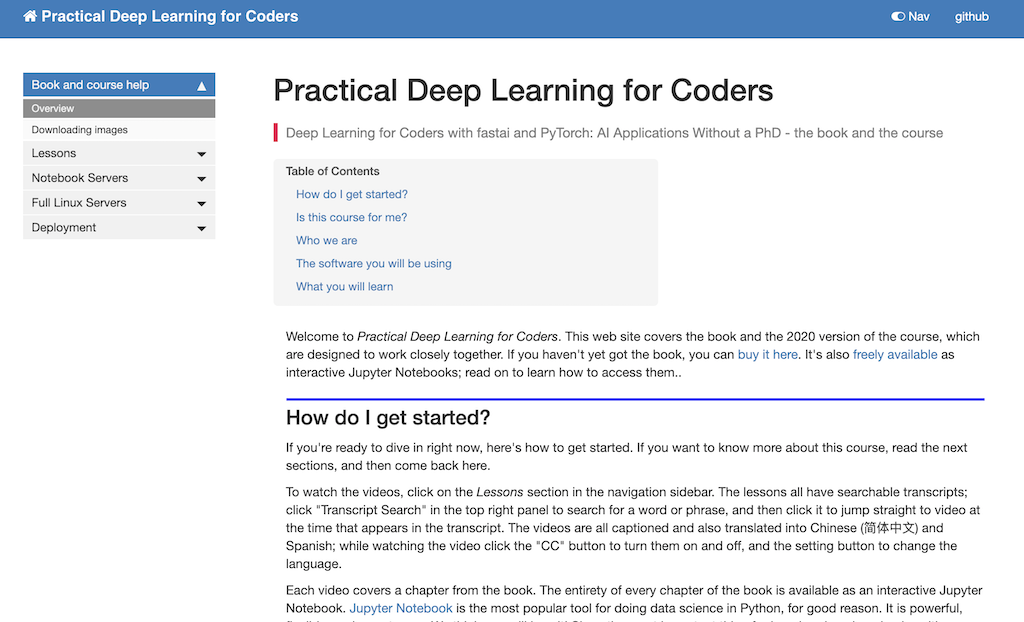
https://course.fast.ai/
Unter “Lessons” finden sich die Lektionen. Unter “Notebook Servers” findet man die Notebooks. Und die Notebooks auszuführen gibt es mehrere Möglichkeiten:
- Google Collab
- Amazon AWS EC2
- JarvisLabs.ai [best value]
Am einfachsten ist es, mit Google Collab anzufangen. Es ist außerdem kostenlos, speichert aber Daten nicht dauerhaft, die Sessionlänge ist beschränkt und es erfordert bei jedem Neustart Installationen.
Für “echte” Projekte oder Startups wird man sicher irgendwann auf Amazon AWS stoßen, da es von den meisten Firmen verwendet wird. Es kostet 50-60 cent pro Stunde und dort werden Daten dauerhaft gespeichert.
In dieser Lektion zeigt Howard wie man mit Collab und AWS verwendet.
Mein Kommentar: Man kann natürlich auch den eigenen Computer verwenden, muss dafür aber einiges installieren und braucht eine leistungsfähige Grafikkarte oder GPU (GPU=graphic processing unit).
Ich habe mir auf Basis von Tim Dettmers hervorragenden Artikeln (z.B. A Full Hardware Guide to Deep Learning https://timdettmers.com/2018/12/16/deep-learning-hardware-guide/) vor einiger Zeit mal eine eigene Deep Learning Machine zusammengebaut: https://frankwolf.blog/2019/01/26/bau-meiner-extendable-deep-learning-machine-deep-al/
Google Collab (23:45)
Um mit Google Collab zu beginnen, klickt man auf das Notebook, dass man öffnen möchte, siehe Bild: 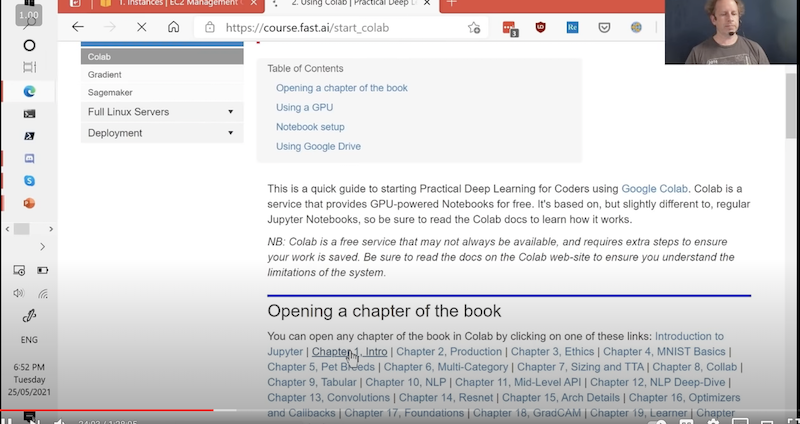
Und die Notebook öffnet sich in Google Collab.
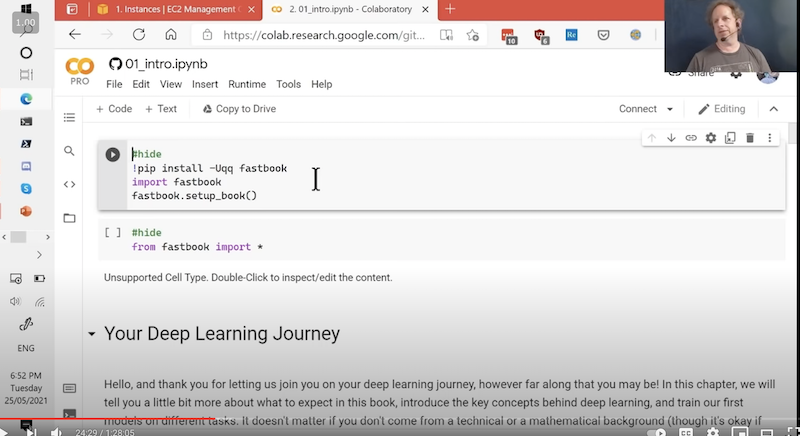
Vor der Ausführung des Notebooks sollte man auswählen, dass man eine GPU verwenden möchte. Das macht man, indem man unter Runtime -> Change runtime type und dann unter Hardware accelerator “GPU” auswählt und mit “Save” bestätigt. Das Training des Modells wird sich so um mehrere 100x beschleunigen.
Da Google Collab nicht persistiert, muss in dem Notebook nichts mehr aufgesetzt und installiert werden. Daher muss man immer die erste Zelle erneut ausführen (weißes Play-Zeichen auf weißem Grund). Dieses Zeile:

installiert alles, was nötig ist, damit der Kurs funktioniert. Wenn die Zelle durchgelaufen ist, kann man optional Google Collab mit Google Drive verknüpfen und so Notebooks sichern:
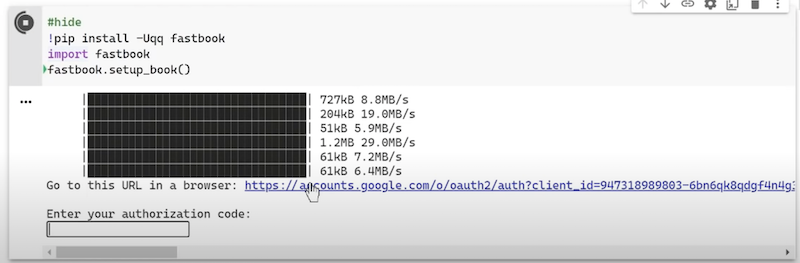
Den Link hinter “Go to this URL in a browser” anklicken, die Verknüpfung bestätigen und den Bestätigungscode, der im Browser nach der Verknüpfung erscheint kopieren und in das Feld: “Enter your authorization code:” eingeben.
Durch das Ausführen dieser Zeile werden alle installierten Ressourcen geladen; anklicken und wieder den Play-Button bestätigen.
Scrollt ihr im Notebook jetzt weiter herunter, seht ihr, dass es sich bei den Inhalten in der Tat um das Deep Learning Buch von Jeremy Howard handelt. Man kann es lesen und direkt darin an vorgesehenen Stellen arbeiten (oder eigene Zellen einfügen und dort experimentieren).
Das erste Modell (27:20)
Scrollt man weiter, stößt man irgendwann auf diese Zelle:
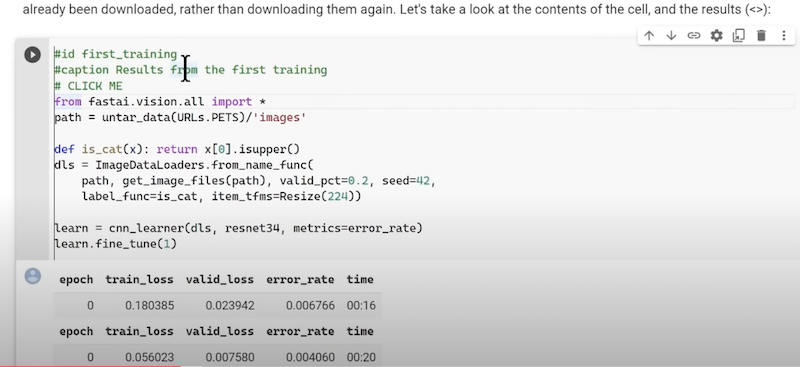
Sie beinhaltet alles, was nötig ist, um ein Modell zu erstellen. Play-Button anklicken. Es passiert nun folgendes:
- Herunterladen von 10.000en Bildern mit Katzen und Hunden
- Basierend auf den Dateinamen werden die Bilder Katzen und Hunden zugeordnet (Labelling)
- Dann wird ein vortrainiertes Modell heruntergeladen, das bereits gelernt hat verschiedene andere Bilder zu erkennen
- Anschließend wird dieses Modell als Grundlage genommen, um es mit Hilfe der heruntergeladenen Bilder darauf zu trainieren, besonders gut Hunde von Katzen zu unterscheiden
- Abschließend prüft es, wie gut das neue Modell darin ist, Hunde von Katzen zu unterscheiden.
Dieser Prozess kann ggf. mehrere Male wiederholt werden, während das Modell besser und besser wird. In jeder Wiederholung (auch Epochs oder Epoche genannt) geht der Trainingsvorgang einmal alle Bilder durch, zeigt sie dem Modell inklusive der Feststellung, ob es sich beim gezeigten Bild um einen Hund oder eine Katze handelt, bis alle Bilder gezeigt sind, wobei das Modell schrittweise besser wird.
Info: Diese Zeilen im Notebook sind nicht für den Code relevant, sondern für die Erstellung des PDFs/Buches und können daher ignoriert werden.

Notebook von GitHub öffnen für die Lernschritte “Notebook ausführen & experimentieren” sowie die “Ergebnisse reproduzieren” (29:40)
Klickt man unter File auf Open notebook:
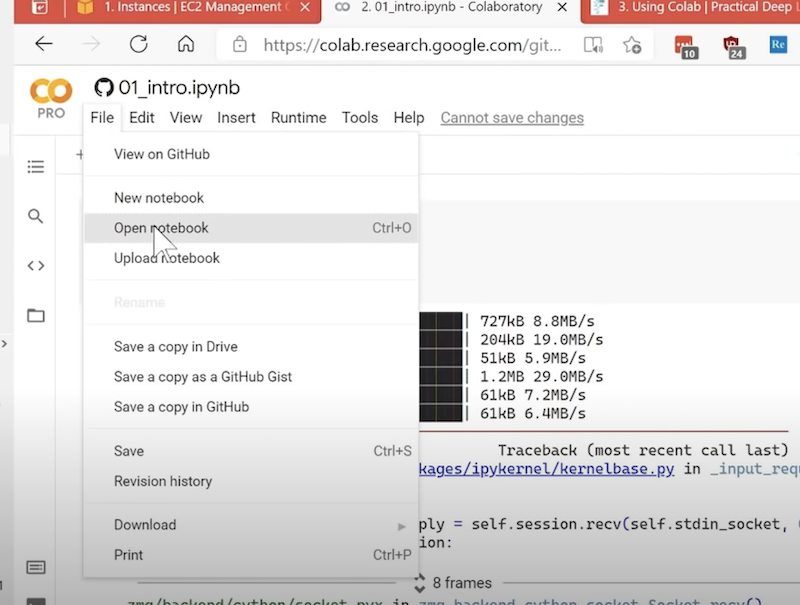
öffnet sich dieses Fenster und man klickt auf “GitHub”:
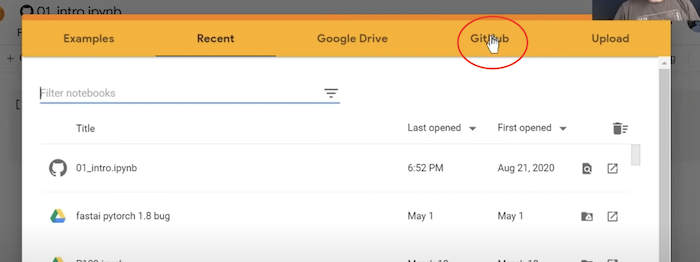
Es öffnet sich die Liste der Notebooks des fastai/fastbook repos:
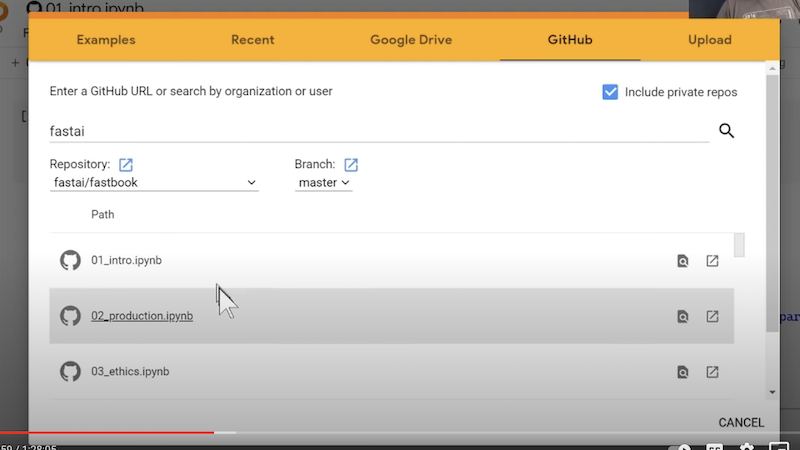
Scrollt man die Liste runter, sieht man, dass es zu jedem Notebook zu jeder Lektion eine Kopie gibt die clean/<Lektion-titel> heißt:
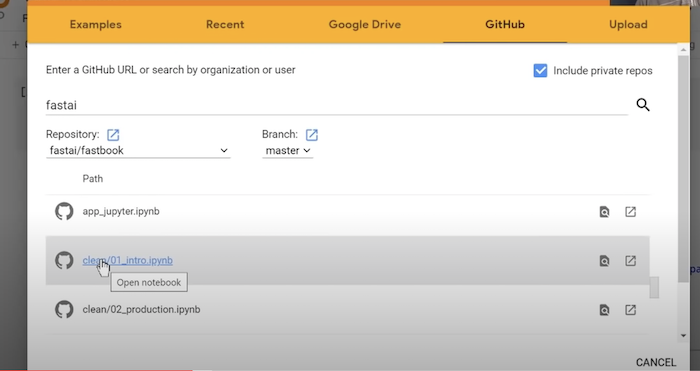
Diese enthalten nur noch Überschriften und Code und sollen helfen die Lernschritte:
- “Notebook ausführen & experimentieren” und
- “Ergebnisse reproduzieren”
auszuführen.

Für jede Zelle überlege nun:
- Warum ist die Zelle hier?
- Wofür ist sie da?
- Was wird sie tun?
- Wie wird der Output aussehen?
Das soll helfen, aktiver zu lernen.
Ganz unten in jedem clean notebook finden sich Fragen. Diese kann man zur Selbstkontrolle nutzen. Die Antworten stehen immer im Buch bzw. in den vollständigen Notebooks.
Die eigene Arbeit teilen (32:32)
Sobald du bereit bist, erstelle etwas, das dir gehört. Dazu ist der letzte Lernschritt: Mit anderen Daten wiederholen da. Nutze für Fragen jederzeit das Forum: https://forums.fast.ai/. Und wenn du soweit bist, suche nach dem Artikel: “Share your work”. Siehe hier:
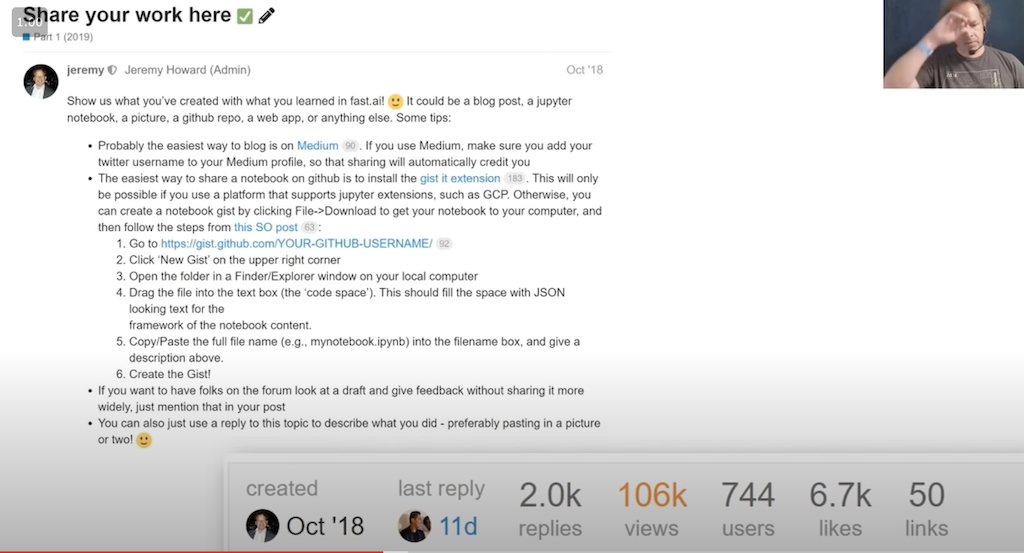
Hangele dich an dieser Anleitung entlang, um eigene Arbeiten im Forum zu posten. Unter den Antworten finden sich viele Beispiele von Arbeiten, die Leute nach der ersten Kurswoche gemacht haben, die auch als Inspiration für eigene Ideen dienen können.
Howard sagt: Es wäre toll, wenn auch du antworten könntest! Ein Bild oder Link zu dem, was du gebaut hast.
Die Atmosphäre ist ermutigend und positiv, also keine Scheu! Niemand wird sagen: “Aah, das hab ich ja schon vor Jahren gemacht.” im Gegenteil, alle freuen sich über neue Leute und neue Beiträge!
Wie man nicht fast.ai macht. (34:28)
Hier bezieht sich Jeremy wieder auf einen Auszug aus Radeks Buch:

Freie Übersetzung: Weil ich niemanden kannte, der selbst Software-Entwickler war, recherchierte ich im Internet und bald hatte ich ein Curriculum zusammengestellt: dem Internet zufolge musste ich nur etwas Analysis, Lineare Algebra, Wahrscheinlichkeitstheorie lernen und ich wäre fertig. Easy peasy.
Analysis schien ein guter Ausgangspunkt zu sein und Kurse der beste Unis waren im Netz nur einen Mausklick entfernt. Allerdings benötigte man für manche Beweise der Analysis weiteres Wissen. Kein Problem, Walter Rudis “Prinzipien mathematischer Analysis” war die Rettung, aber was war das? Offenbar musste man, um das wirklich zu verstehen auch noch Mengenlehre lernen.
Jeremy Howard dazu: Es gibt viele Gatekeeper da draußen, die sagen: “Wenn du ein echter Deep Learning Praktiker sein willst, musst du erst einen Fortgeschrittenen-Kurs zu Linearer Algebra durchgearbeitet haben” etc. Die Wahrheit ist, du brauchst aus der Linearen Algebra eigentlich nur Matrix-Multiplikation. Und das besteht im Kern aus der Multiplikation einiger Zahlen und dem Summieren dieser Zahlen. Das ist schnell gelernt.
Keine Sorge: Man kommt mit der Zeit zu den Grundlagen, wenn man das will. Sie sind aber keine Voraussetzung, um anzufangen. Im Gegenteil: Während du mathematische Theorie lernst, programmierst du nicht, experimentierst du nicht, baust du keine echten Deep Learning Modelle.
Und, wenn du diesem Kurs folgst, und eigentlich gar keine Deep Learning Modelle bauen willst, ist das nicht der richtige Kurs für dich. Wenn’s aber dein Ziel ist, lerne nicht erst die ganze mathematische Theorie.
Feedback (36:46)
Wenn du echte Modelle trainierst, bekommst du Feedback. Die meisten sind überraschst, wie schnell sie bereits Deep Learning Modelle trainieren können.

Daher starte direkt praktisch.
Der beste Weg als Software-Entwickler besser zu werden: Code lesen, Code schreiben (37:30)
Übersetzung: “Du schärfst deine Fähigkeiten nicht durch Ressourcen, Bücher oder Artikel. Du schärfst deine Fähigkeiten durch Übung. Wenn du besser werden willst, tue Dinge.”
Nach dem Abschluss des Kurses kann man ein noch besserer Entwickler werden. Und das wird man durch das Lesen und Schreiben von Code, insbesondere Deep Learning Code. Der fast.ai Sourcecode ist designt, um gut lesbar zu sein, du könntest also den lesen.
News zu Deep Learning – was ist aktuell los: Twitter (38:08)
Jeremy Howard sagt, die beste Quelle ist Twitter. Das sind drei der Tweets die an dem Tag, an dem er die Präsentation erstellt hatte, als erste in seinem Feed auftauchten. Die ganze Deep Learning Community ist auf Twitter.
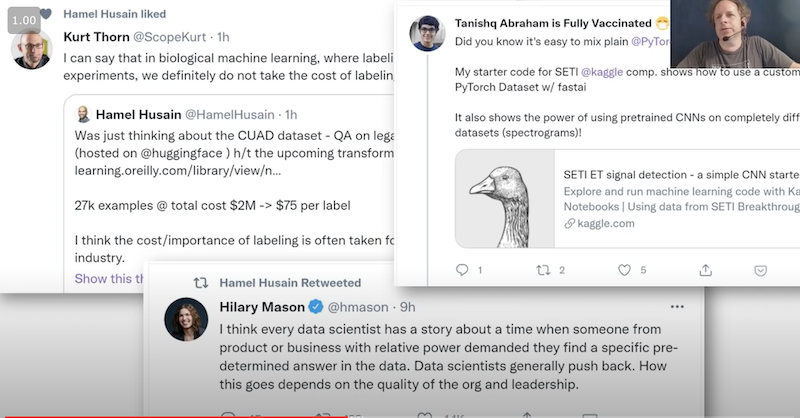
Um Menschen zu finden, denen man für gute Deep Learning Themen folgen kann, empfiehlt er, in Twitter zu seinem Profil (https://twitter.com/jeremyphoward) zu gehen, seine Likes (https://twitter.com/jeremyphoward/likes) anzuschauen und Tweets zu finden, die man auch mag. Anschließend kann man den Leuten, die diese Tweets geschrieben haben, folgen. So und durch die Diskussionen, in die diese Personen involviert sind, kommt man schnell an weitere für einen selbst interessante Personen und bald hat man 100 Leute, denen man folgt und jeden Tag neue interessante Infos zum Thema Deep Learning im eigenen Twitter-Feed.
Natürlich kann man auch Leuten, deren Arbeit man doch nicht interessant findet, wieder unfollowen.
Natürlich kann man auch selbst hier zum Thema tweeten, um Beachtung zu finden.
Warum du (ja, du!) bloggen solltest (40:36)
Neben Twitter solltest du anfangen zu bloggen. Schreibe über etwas, das du selbst vor 6 Monaten interessant gefunden hättest.
Rachel Thomas, fast.ai Partner von Jeremy Howard, hat dazu mal diesen Artikel geschrieben: https://medium.com/@racheltho/why-you-yes-you-should-blog-7d2544ac1045
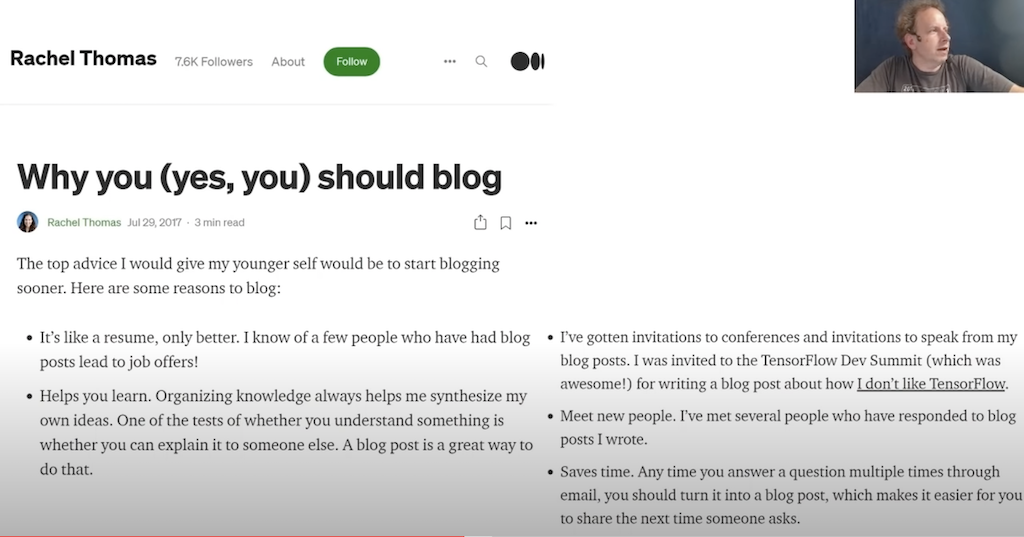
Jeremy Howard empfiehlt, für den einfachen Start fastpages zu nutzen: https://fastpages.fast.ai/
Alle Artikel sind in GitHub (wodurch man dann mehr darüber lernen kann) und in Markdown (was man auch lernen sollte) geschrieben.
Worüber man bloggen kann: Nehmt ein Video z.B. von Jeremy und verwandelt es in einen Blog Post. Man kann natürlich auch Videos von anderen Personen nehmen.
Vorteile:
- Wenn jemand einen Post von Jeremy aufschreibt, freut er sich, weil sein Talk nun auch in einem weiterem Medium zur Verfügung steht
- Manche Leute lesen lieber, als Videos anzusehen, also hat es einen Nutzen für diese Leute
- Das wiederum gibt demjenigen, der den Talk gehalten hat, Following von anderen Leuten, die lieber nur lesen
- Und: Man lernt natürlich den Inhalt besser, wenn man die Themen aufschreibt
Wie unterscheidet sich Maschine Learning von anderen Formen des Programmierens? (44:08)

Der Schlüssel ist, dass wir generalisieren können. Man kann ein Modell mit Hilfe eines Datensatzes trainieren und es dann auf andere, neue, noch nicht gesehen Daten anwenden und immer noch gute Resultate bekommen.
In diesem Kurs werden Modelle gebaut, die gut generalisieren. Und wir lernen, wie man messen kann, wie gut sie generalisieren.
Die Antwort auf die Frage, ob wir dem Modell vertrauen können, ist absolut zentral für Kaggle-Wettbewerbe oder auch Produkte, die wir bauen.
Die Bedeutung des Validierens (45:17)
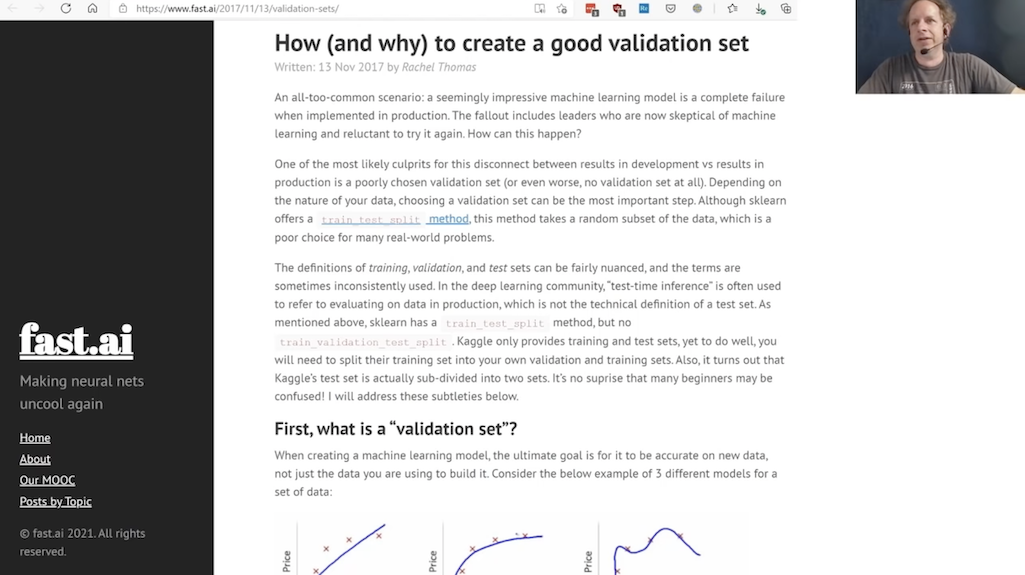
Um zu messen, ob unser Modell gut ist, benötigen wir die sogenannte Validierung, und dafür ist ein Validierungsdatensatz nötig. Daher kommt dieses Thema bereits in der ersten Woche vor. Man benötigt dafür einen Datensatz, der möglichst gut repräsentiert, welche Daten das Modell im real world Einsatz bewerten können soll.
Dazu hat Rachel Thomas, Jeremys Partner, diese Text geschrieben: https://www.fast.ai/2017/11/13/validation-sets/
Hier wieder eine Anekdote zum Bloggen: Rachel schrieb diesen Post basierend auf einem Talk, den Jeremy in San Francisco hielt und letzten Endes war dieser Blogpost deutlich einflussreicher als der Talk.
Writing Maschine Learning Code is hard (46:22)

Jeremy sagt, er geht davon aus, dass jede Zeile, die er schreibt, falsch ist. Und das stimmt regelmäßig. Leider ist das viel schwieriger als in anderen Disziplinen der Software-Entwicklung.
Am besten man beginnt mit einem simplem Baseline Ansatz. Ein solcher Ansatz kann z.B. sein, den Mittelwert beider Werte zu nehmen.
Besser keine komplizierten neuen Ansätze aus dem Nichts schreiben, wenn später etwas nicht funktioniert, kann es alle möglichen Gründe haben: Die Idee kann schlecht sein, oder es ist einfach irgendwo ein einfacher, aber nicht offensichtlicher Fehler im Code.
Auf dieser Art erstellt niemand erfolgreiche neue Machine Learning Software. Am besten ist es, eine erste einfache Lösung zu erstellen, die das Problem von vorne bis hinten löst und darauf aufzubauen.
Dieses Problem tritt überall auf. Jeremy teilt dazu eine Geschichte eines Silicon Valley Startups, das versucht, für einen bestimmten Fall gesunde von kranken Menschen zu unterscheiden. Statt sofort ein kompliziertes Modell zu bauen, empfahl er: nehmt den Durchschnitt der beiden Gruppen und nehmt diesen Mittelwert als Baseline-Trennwert für die Unterscheidung der Gruppen und versucht nun ein Modell zu bauen, dass besser ist als diese einfache Heuristik.
Es ist sehr wichtig, ob das Modell, das man baut wirklich etwas sinnvolles vollbringt.
Wie man einen Kaggle Wettbewerb gewinnt (49:53). Howards empfiehlt an Kaggle Wettbewerb teilzunehmen. Selbst wenn man letzter wird, bedeutet es, dass man in der Lage ist den ganzen notwendigen Prozess für die Entwicklung eines Machine Learning Modells auszuführen. Vom letzten Platz kann man sich dann durch Iteration auch verbessern. Hier kommt wieder die Zähigkeit ins Spiel. Wettbewerbe sind auch darum sinnvoll, weil man sich auf ein Modellproblem konzentrieren kann, statt wie bei echten Projekten von Softwareentwicklung und Deployment etc abgelenkt zu werden. Howard empfiehlt: Fange mit einem neuen Wettbewerb so früh wie möglich an und tue jeden Tag etwas dafür: lese im Kaggle forum, verbessere den Code, teste ein neues Modell etc.. Dann ist es wahrscheinlich, dass man bereits zu den besten 50% in der Wettbewerb gehört. Versuche es aus!
Wie man einen Job findet (52:35). Es gibt verschiede Möglichkeiten Deep Learning beruflich einzusetzen:
- Deep Learning in deine Organisation bringen
- eine neue Stelle/Rolle in deiner Firma finden
- eine neue Stelle als Data Scientist oder Researcher in einer anderen Organisation zu finden
TIps:
- Ein Doktor in Mathe ist weniger wichtig, als dein Portfolio praktischer Projekte (inklusive deiner Beiträge in Blogs, im fast.ai Forum, Tweets, Discord etc.)
- Jeder der fast.ai Alumni, die Howard als effektive Community Member aufgefallen sind, haben heute einen sehr guten Job.
- Jobs in große, “alten”, etablierten Unternehmen findet man so eher nicht, da diese über Personalmanagement gehen und die mehr auf formale Errungenschaften Wert legen
- Bei Startups, kleinere und agilere Unternehmen kann man sich aber gut bewerben und hat gute Chancen sich dort anschließen zu können
- Schließlich gibt es auch die Möglichkeit ein eigenes Geschäft zu starten
- Daher: je früher man anfängt etwas für sein Portfolio zu tun, umso besser!
Erfahrung von mir: wenn man erst mal zu seinen ersten Jobs gekommen ist, hat man auch die formalen Errungenschaften in Form ebendieser Jobs und kann sich dann auch bei etablierte Firmen vorstellen, wenn man das will.
Kurs 1 ist Vorbereitung für Kurs 2 (55:38)
Vorteile eines AWS EC2 Severs (56:13)
- AWS bietet echte Linux Server
- Die Arbeit, die man dort tut ist nicht nach einem Neustart verloren – wie bei Collab
- Kosten 50 Cent pro Stunde
Aufsetzen eines AWS EC2 Severs (57:16)
Hinweis: Wenn ihr dazu eine Anleitung auf Deutsch wollt, kommentiert hier gern, dann versuche ich das umzusetzen.
Tip: AWS hat viele Produkte mit schwer zu merkenden Namen, wir brauchen hier EC2
Antworten auf Fragen
Jeremy sagt, für ihn ist Deep Learning in den Projekten an denen er arbeitet das nützlichstes Modell im Vergleich zu anderen Machine Learning Algorithmen (1:14:00)
Jeremy Howard erklärt, das Teil 1 des Kurses einem hilft ein guter Praktiker zu sein, dass aber Teil 2 nötig ist, um wirklich neue Dinge zu bauen, und er findet, das zu wenig Leute den Teil 2 abschließen. (1:19:00)
Über Experiment Tracking Software: Jeremy meint: Tensorboard und Weights and Biases sind am besten. Weights und Biases noch etwas besser als Tensorboard. Er selbst benutzt beides nicht und rät davon ab, weil sie ablenken. Man sollte – während ein Experiment läuft – lieber schon an der nächsten Iteration oder an etwas anderem arbeiten, statt dem Verlauf des Experiments zu folgen (1:22:50)
Experiment Tracking Software: gibt dir in Echtzeit Feedback zum Verlauf des Modelltrainingsprozess.
Tips: Habt ihr Probleme schaut auf jeden Fall in die fast.ai Foren. Es sehr wahrscheinlich, das schon jemand vor euch dasselbe oder ein sehr ähnliches Problem hatte und andere helfen konnten es zu lösen.