In diesem Tutorial gehen wir alles durch, was nötig ist, um mit terraform auf ein Droplet aufzusetzen.
Code: https://github.com/genughaben/terraform-digitalocean-droplet
1 Vorbereitung
- Terraform installieren. Auf Linux könnt ihr dazu mein Tutorial aus meinem letzten Artikel nehmen: https://frankwolf.blog/2019/10/06/terraform-unter-linux-installieren/
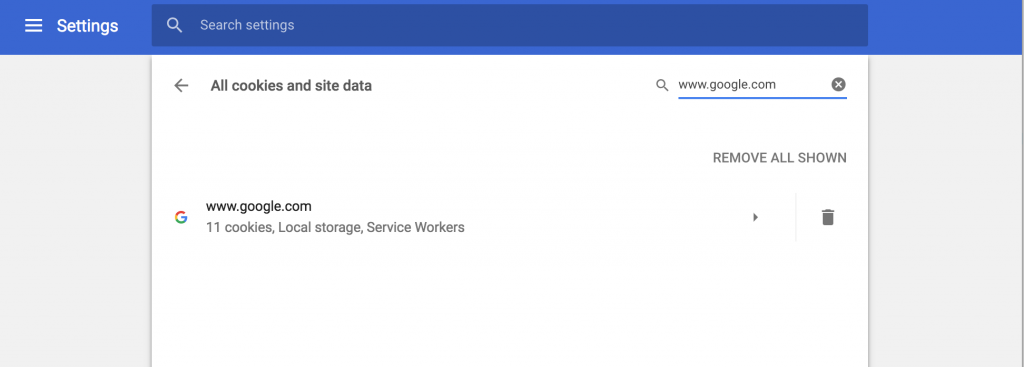
- Registrieren / Anmelden bei Digital Ocean: Wenn ihr noch angemeldet seid, registriert euch bei Digital Ocean
- API Key auf Digital Ocean anlegen:
- Geht unter API auf “Generate New Token”.
- Gebt dem Token einen Namen (z.B. terraform-do) und
- stellt sicher, dass der Token Lese und Schreibrechte hat (Haken bei Rad und Write setzen)
- Klickt auf “Generate Token”
- Nun wird ein Hash-Key angezeigt, den ihr euch sofort kopieren und in einer Textdatei zwischenspeichern solltet, da er nur einmal angezeigt wird.
- SSH-Schlüssel erzeugen und auf Digital Ocean eintragen
- Im Terminal:
- > ssh-keygen -t ecdsa
- > /home/<user-name>/.ssh/dokey
- Lasst das Passwort leer: also zweimal Enter drücken [Leider nötig, damit es von terraform benutzt werden kann]
- Prüft durch eingabe von:
- > ls /home/<user-name>/.ssh
- Das im Ordner jetzt dokey und dokey.pub vorhanden sind
- Kopiert jetzt euren öffentlichen Schlüssel in die Zwischenablage:
- >cat /home/<user-name>/.ssh/dokey.pub
- Kopiert euch jetzt die ausgegebenen zwei Zeilen, die in etwa so aussehen:
-
- ecdsa-sha2-nistp256 ganzVieleZufäaaLl!1igeZa4hlenU6ndB6chst4aben= <user-name>@<machine-name>
- Klickt jetzt in eurem digital ocean Profil auf “Account” und
- dann auf “Security” und
- dann auf “Add SSH Key”
- fügt den öffentlichen Schlüssel ein und
- gebt ihm einen Namen “z.B. terraform-do”
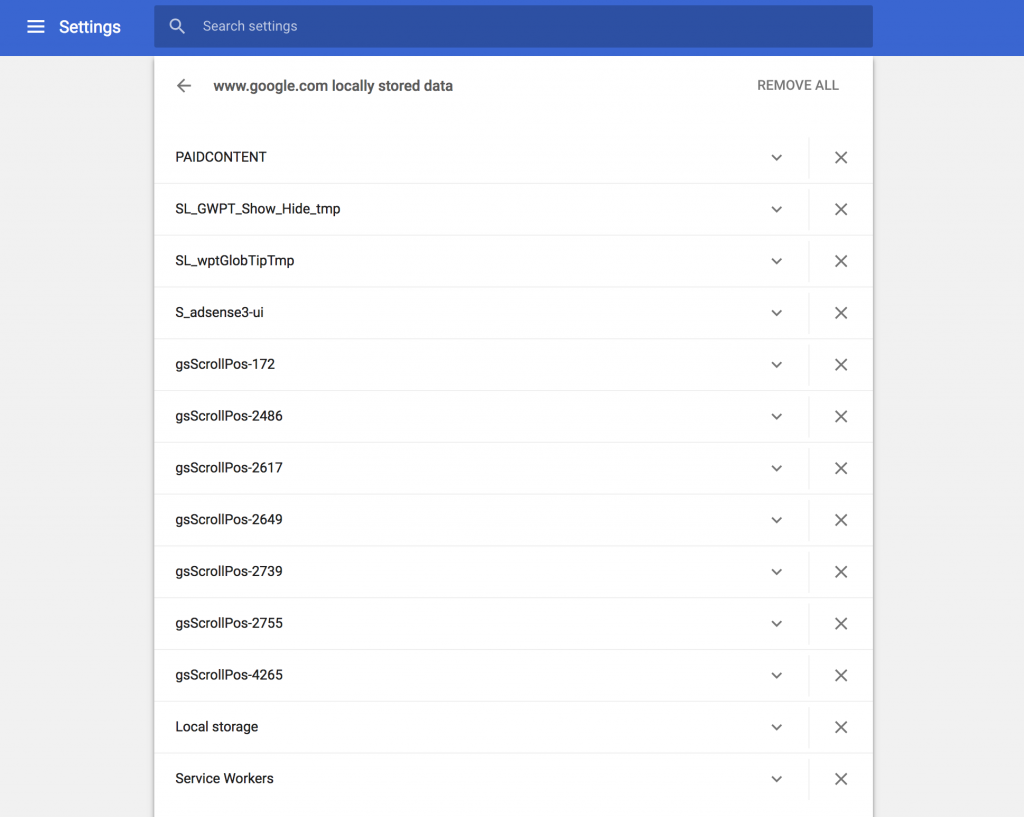
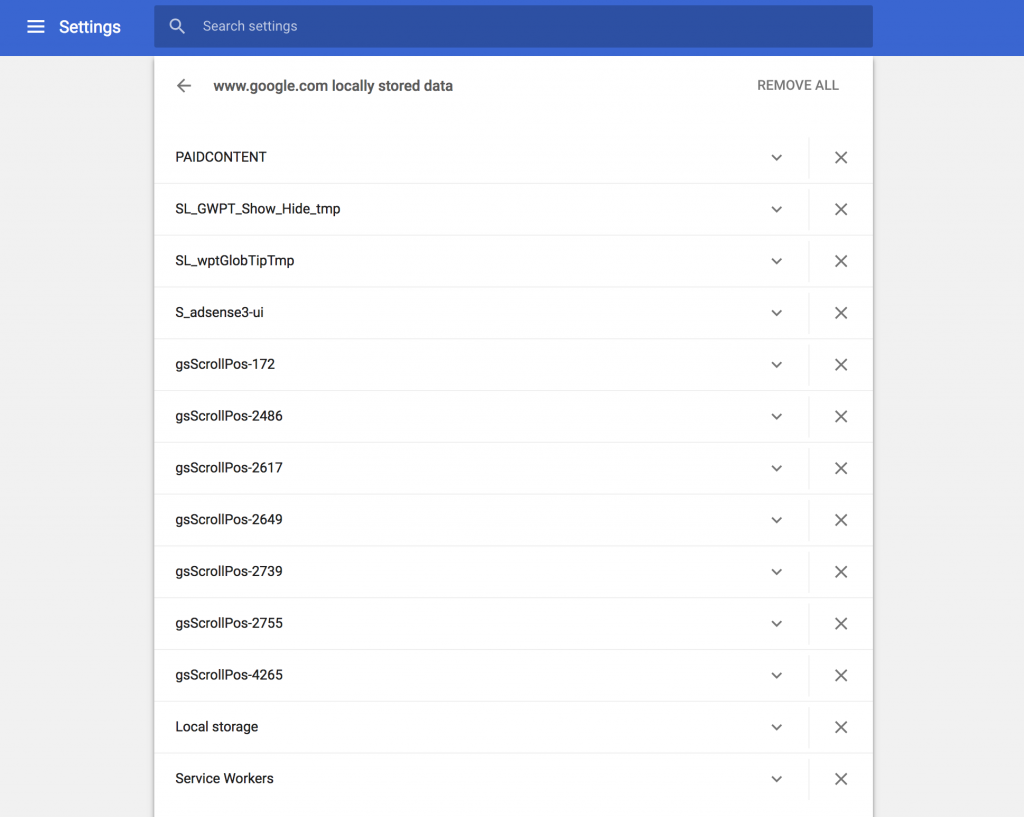
- Jetzt werden in der Liste der SSH-Keys der neue Key angezeigt, kopiert euch dort jetzt den berechneten MD5-Hash durch klick auf Copy und kopiert euch diesen für den Moment z.B. in diesselbe Textdatei, in der ihr auch schon euren API-Token gespeichert habt.
2 Providers und Ressources
tl;dr: Provider (wie Digital Ocean) stellt die Ressourcen (VMs) zur Verfügung, die wir mit terraform anfragen, erstellen, verwalten, ändern und zerstören können.
ts;wm
Providers
Terraform wird verwendet, um Infrastrukturressourcen wie physische Maschinen, VMs, Netzwerkswitches, Container und mehr zu erstellen, zu verwalten und zu aktualisieren. Fast jeder Infrastrukturtyp kann als Ressource in Terraform dargestellt werden.
Diverse Anbieter bieten API an, über die ihr Ressourcen nutzen könnt. Anbieter sind dabei IaaS-Anbieter wie z.B. Alibaba Cloud, AWS, GCP, Microsoft Azure, OpenStack oder PaaS wie z.B. Heroku oder SaaS-Services wie z.B. Terraform Cloud, DNSimple, CloudFlare.
Wir werden hier Digital Ocean als Provider verwenden.
Resources
Ressourcen sind das wichtigste Element in der Sprache Terraform. Jeder Ressourcenblock beschreibt ein oder mehrere Infrastrukturobjekte, wie z. B. virtuelle Netzwerke, Recheninstanzen oder übergeordnete Komponenten wie DNS-Einträge.
3 Digital Ocean Provider und Ressourcen
Wir interessieren uns hier für den DO Provider und dessen Ressourcen.
Wir interessieren und hier für die Droplet-Ressource.
4 Projekt aufsetzen
Erstellt, wo für euch auf eurem System sinnvoll einen Projektordner und erstellt vier Dateien:
> mkdir terraform-example
> cd terraform-example
> touch variables.tf
> touch provider.tf
> touch webserver1.tf
> touch webserver.sh
Und kopiert folgende Inhalte in die Dateien:
variables.tf
variable "do_token" {
type = "string"
description = "Dein Digital Ocean API token"
default = "<1. zwischengespeicherten Wert eingeben>"
}
variable "ssh_fingerprint" {
type = "string"
description = "Dein Digital Ocean SSH-Schlüssel-Fingerprint"
default = "<2. zwischengespeicherten Wert eingeben>"
}
variable "pub_key" {
type = "string"
description = "Pfad zu deinem öffentlichen SSH-Schlüssel"
default = "/home/<user-name>/.ssh/dokey.pub"
}
variable "pvt_key" {
type = "string"
description = "Pfad zu deinem privaten SSH-Schlüssl"
default = "/home/<user-name>/.ssh/dokey"
}
provider.tf:
provider "digitalocean" {
token = "${var.do_token}"
}
webserver1.tf
resource "digitalocean_droplet" "webserver1" {
image = "ubuntu-18-04-x64"
name = "webserver1"
region = "fra1"
size = "1gb"
private_networking = true
user_data = "${file("webserver.sh")}"
ssh_keys = [
"${var.ssh_fingerprint}"
]
connection {
user = "root"
type = "ssh"
private_key = "${file(var.pvt_key)}"
timeout = "2m"
}
}
webserver.sh
#!/bin/bash
apt-get -y update
apt-get -y install nginx
5 Webserver mit Terraform aufsetzen
In eurem Projektordner gebt ihr im Terminal jetzt ein:
> terraform init
Terraform liest alle .tf-Dateien ein (daher sind deren Namen auch egal) und lädt jetzt eventuell nötige Plugins herunter.
Wenn ihr jetzt folgendes eingebt:
> terraform plan
Mit dieser Eingabe prüft Terraform, welche Resources es bereits managet ( im Moment, keine), was geändert und zerstört werden soll (hier auch nichts) und was erstellt werden soll. Und das ist eine Machine. Eure Ausgabe sollte in etwa so aussehen:
> terraform plan
Refreshing Terraform state in-memory prior to plan...
The refreshed state will be used to calculate this plan, but will not be
persisted to local or remote state storage.
------------------------------------------------------------------------
An execution plan has been generated and is shown below.
Resource actions are indicated with the following symbols:
+ create
Terraform will perform the following actions:
# digitalocean_droplet.webserver1 will be created
+ resource "digitalocean_droplet" "webserver1" {
+ backups = false
+ created_at = (known after apply)
+ disk = (known after apply)
+ id = (known after apply)
+ image = "ubuntu-18-04-x64"
+ ipv4_address = (known after apply)
+ ipv4_address_private = (known after apply)
+ ipv6 = false
+ ipv6_address = (known after apply)
+ ipv6_address_private = (known after apply)
+ locked = (known after apply)
+ memory = (known after apply)
+ monitoring = false
+ name = "webserver1"
+ price_hourly = (known after apply)
+ price_monthly = (known after apply)
+ private_networking = true
+ region = "fra1"
+ resize_disk = true
+ size = "1gb"
+ ssh_keys = [
+ "<euer-SSH-Schlüssel-Fingerprint>",
]
+ status = (known after apply)
+ urn = (known after apply)
+ user_data = "<ein-Hash>"
+ vcpus = (known after apply)
+ volume_ids = (known after apply)
}
Plan: 1 to add, 0 to change, 0 to destroy.
------------------------------------------------------------------------
Note: You didn't specify an "-out" parameter to save this plan, so Terraform
can't guarantee that exactly these actions will be performed if
"terraform apply" is subsequently run.
Die grünlich markierte Ressourcen und ihre Angaben werden im nächsten Schritt über den Digital Oceans Provider an die Digital Ocean API geschickt, die dann ein passendes Droplet aufsetzt.
NB: Die Angaben, bei denen “computed” steht, werden dynamisch berechnet.
Im Moment ist noch nichts passert. Es wurde nur ein Plan erstellt. Ihr könnt in eurem Digital Oceans Dashboard prüfen (Droplets-Menü), dass hier noch keine neue Resource angelegt wurde.
Gebt ihr aber nun:
> terraform apply
ein und bestätigt noch einmal durch eingabe von ‘yes’ (ohne Anführungszeichen!), wird jetzt die beschriebene Resource erzeugt.
Wenn ihr jetzt im Browser eure Droplet-Liste neuladed, erscheint dort ein neues Droplet mit der Bezeichnung “webserver1”!
Gebt ihr die passende IP-Addresse in eurem Webbrowser ein, solltet ihr sehen, dass auf der Maschine durch das Skript in der webserver.sh auch ein NGINX installiert worden sein sollte.
Gratulation! Ihr habt eben euer erstes Droplet mit terraform erzeugt!
Droplet wieder abwracken.
Wenn ihr es wieder loswerden wollt, geht das druch die Eingabe:
> terraform destroy
Bestätigt die Eingabe erneut mit Eingabe von ‘yes’ (ohne Anführungszeichen!)
NB: Ihr müsst für Änderungen in euren Dateien – insbesondere, wenn ihr das, was auf dem Droplet wie in webserver.sh angegeben ändern wollt, nicht selbst jedesmal alle Befehle erneut eingeben. Es reicht – sobald ihr eure Konfigurationsänderung eingegeben habt, erneut
> terraform apply
aufzurufen.
Selbstredend ist dies nur ein Beispiel. Wie schon oben beschrieben könnt ihr auch andere Anbieter nutzen und natürlich vor allem viel kompliziertere Infrastrutur-Setups erreichen, als nur eine Maschine zu starten. Vielleicht dazu in einem anderen Artikel mehr.
Bis dahin: Viel Spaß wünsche ich euch mit Terraform und eurem Digital Ocean Droplet.
p.s.: Ihr braucht mehr Webserver? Weil ihr vielleicht per Load Balancer zwei Maschinen für euren Server verwenden wollt? Die zweite Maschine könnt ihr leicht erzeugen, indem ihr:
> sed 's/webserver1/webserver2/g' webserver1.tf > webserver2.tf
eingebt.
Gebt ihr nun wieder
> terraform plan
ein, seht ihr, dass bei der nächsten Eingabe von terraform apply, zwei Droplets hochgezogen würden.
Ein Beispiel mit Loadbalancer gibt es vielleicht als nächstes.
Quelle: Dieser Artikel basiert auf dem Mini-YouTube-Kurses zu Terraform von tutorialLinux. Ich habe den Artikel aktualisiert, da der Videokurs auf einer älteren Version von terraform aufbaut.