Für den Fall, dass ihr wie ich einmal vergessen habt in eure .gitignore :
__pycache__/
*.py[cod]
einzutragen und nun auf einmal diese Folder auch auf eurem Deploymentsystem habt oder sie bei euch lokal entfernen wollt, um dann zu commiten, dann gebt das hier ein:
Für die meisten meiner Projekte verwende ich gitlab und dessen CI/CD Pipelines. Falls ihr das auch tun wollt, hier einen Anleitung dazu.
Webserver
Um zu beginnen braucht ihr einen eigenen Webserver. Ich habe mir hierfür zu Testzwecken ein simples Droplet bei Digital Ocean geklickt. Das geht so:
auf https://www.digitalocean.com/ registrieren
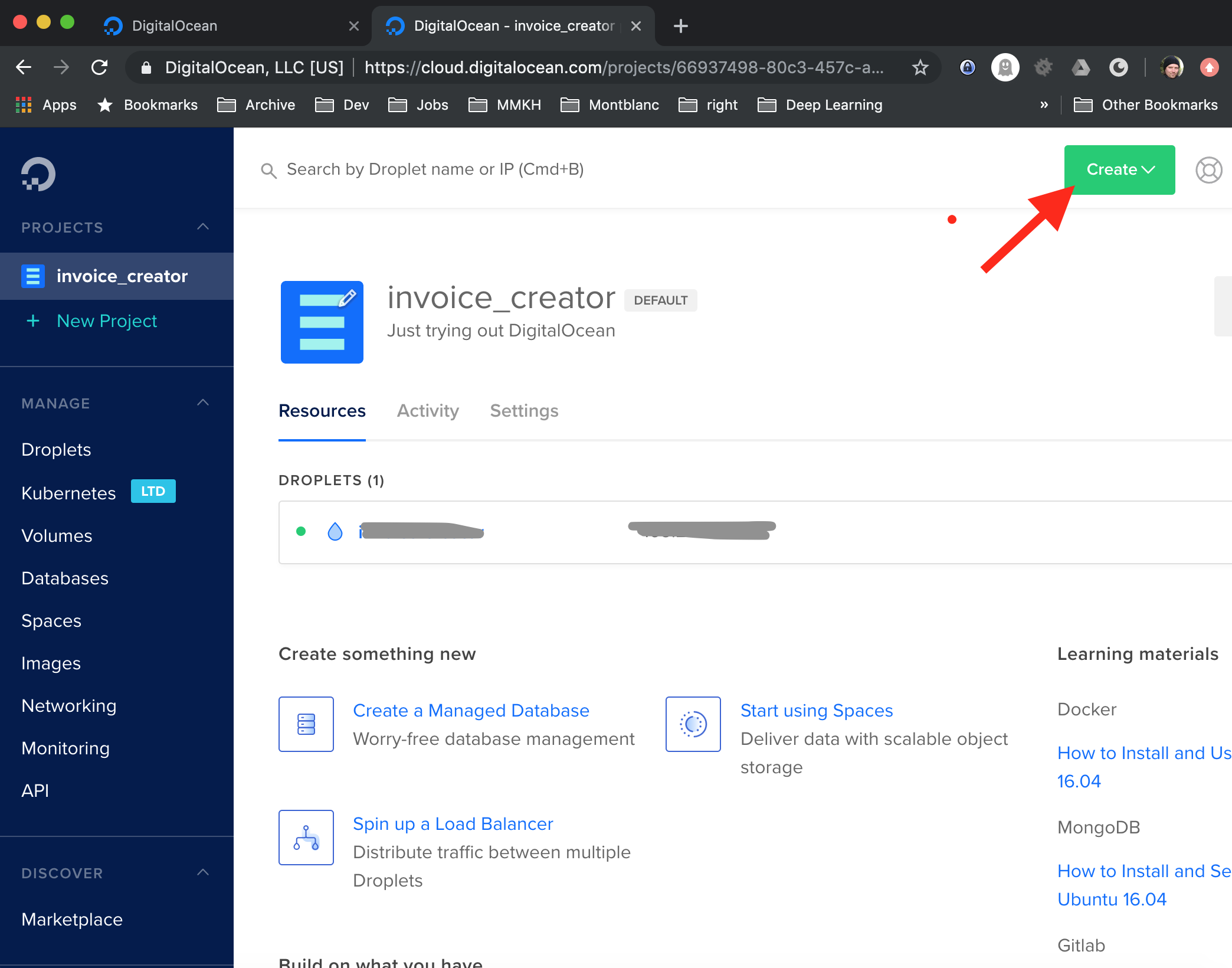
neues Droplet anlegen:
Auf ‘Create’ klicken..
Als nächstes auf ‘Droplet’ klicken…
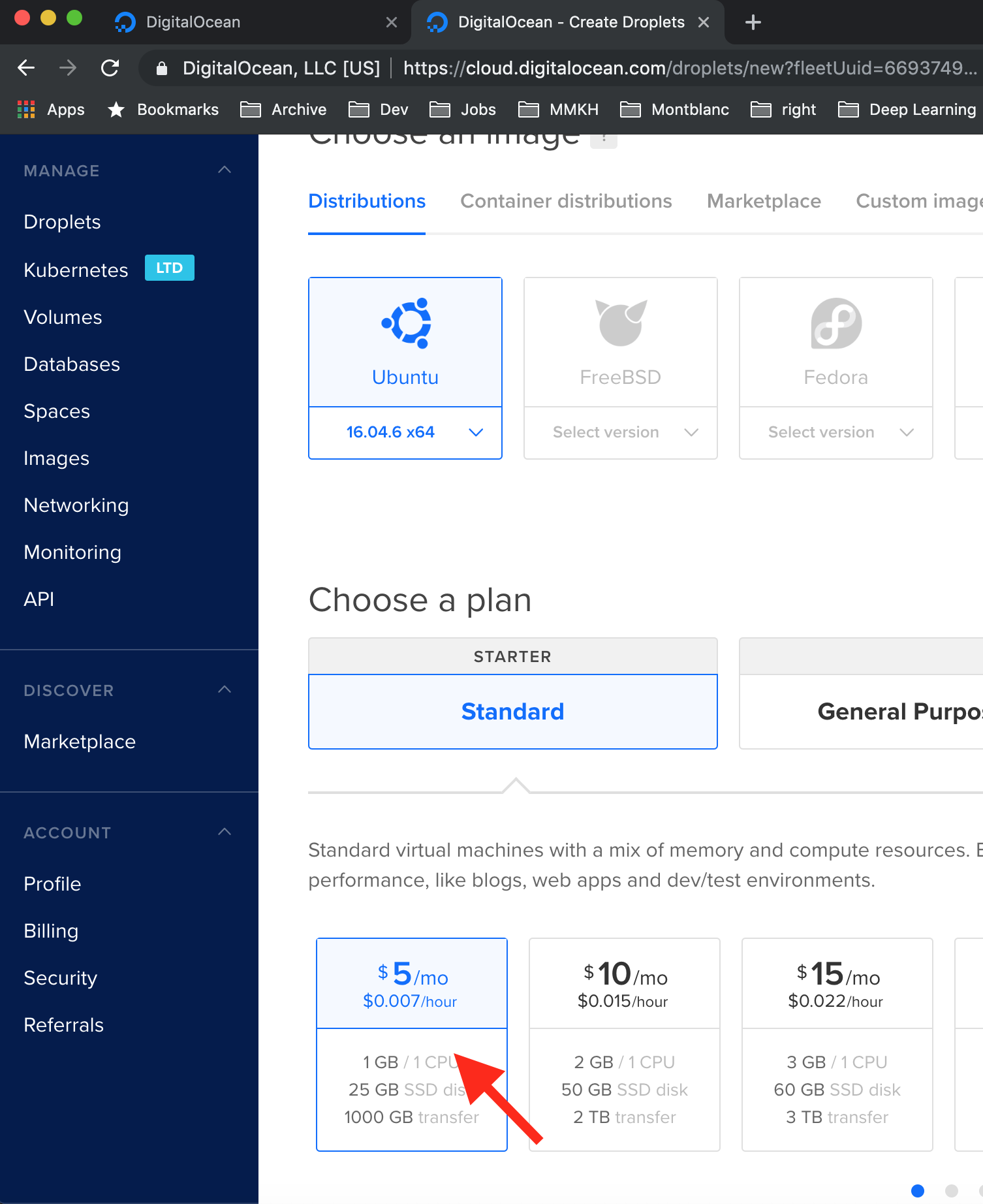
Ich habe eine Ubuntu 16.04 Machine genommen und aus dem “Starter Plan” die kleinste Maschine ausgewählt:
Um sie zu finden, müsst ihr auf den Pfeilknopf links klicken:
Jetzt die gewünschte Machine auswählen:
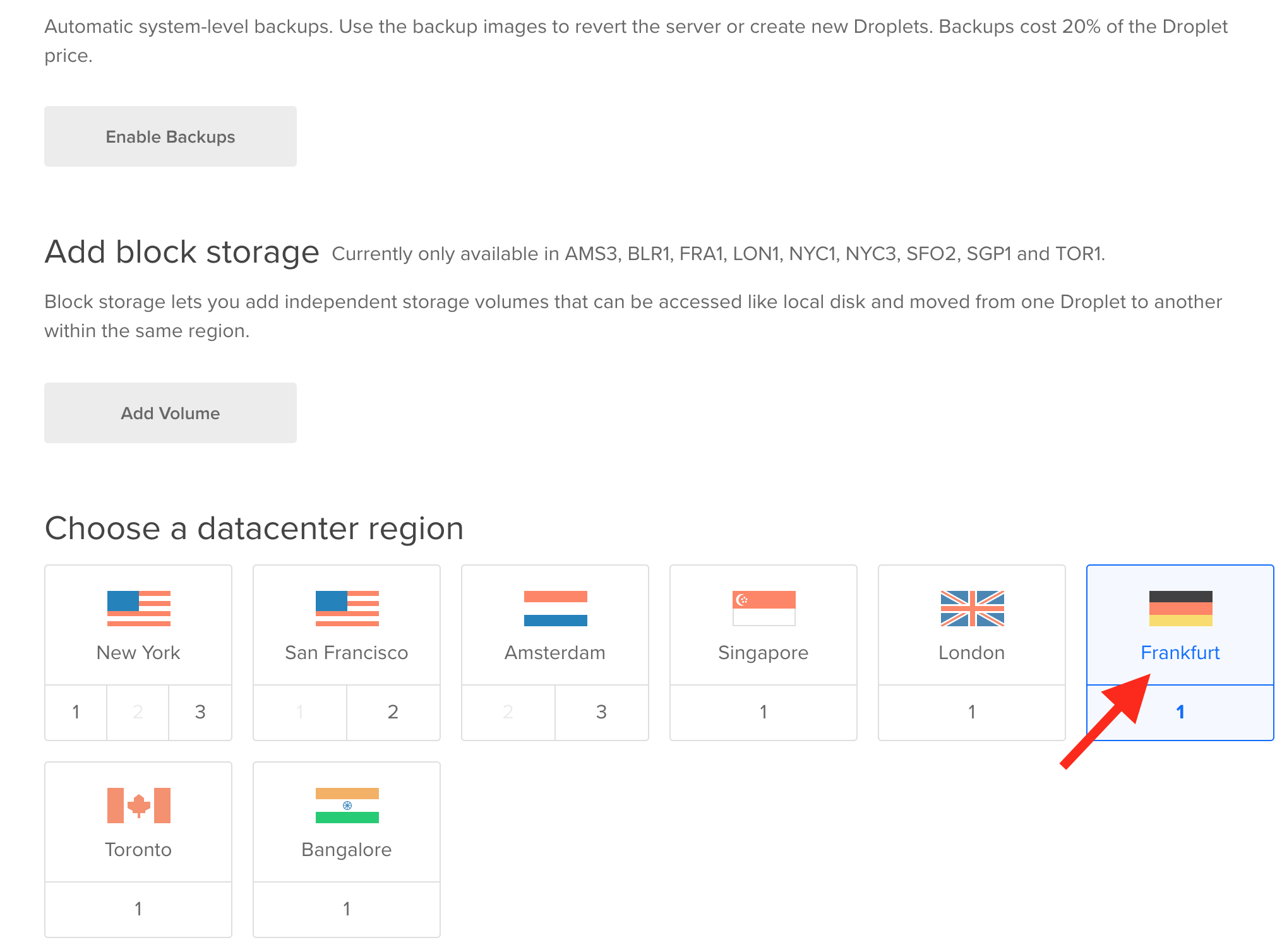
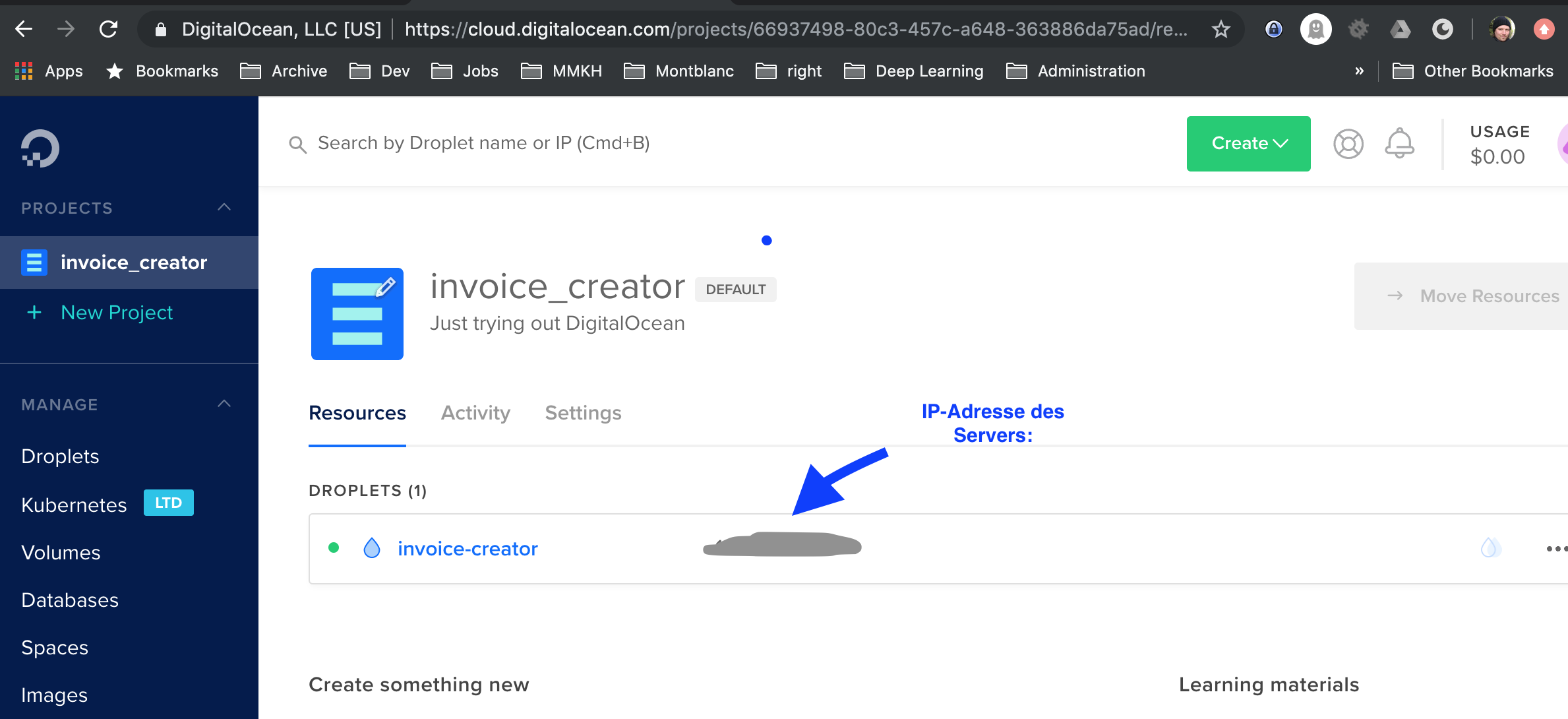
Ich habe das Droplet in Frankfurt erzeugt:
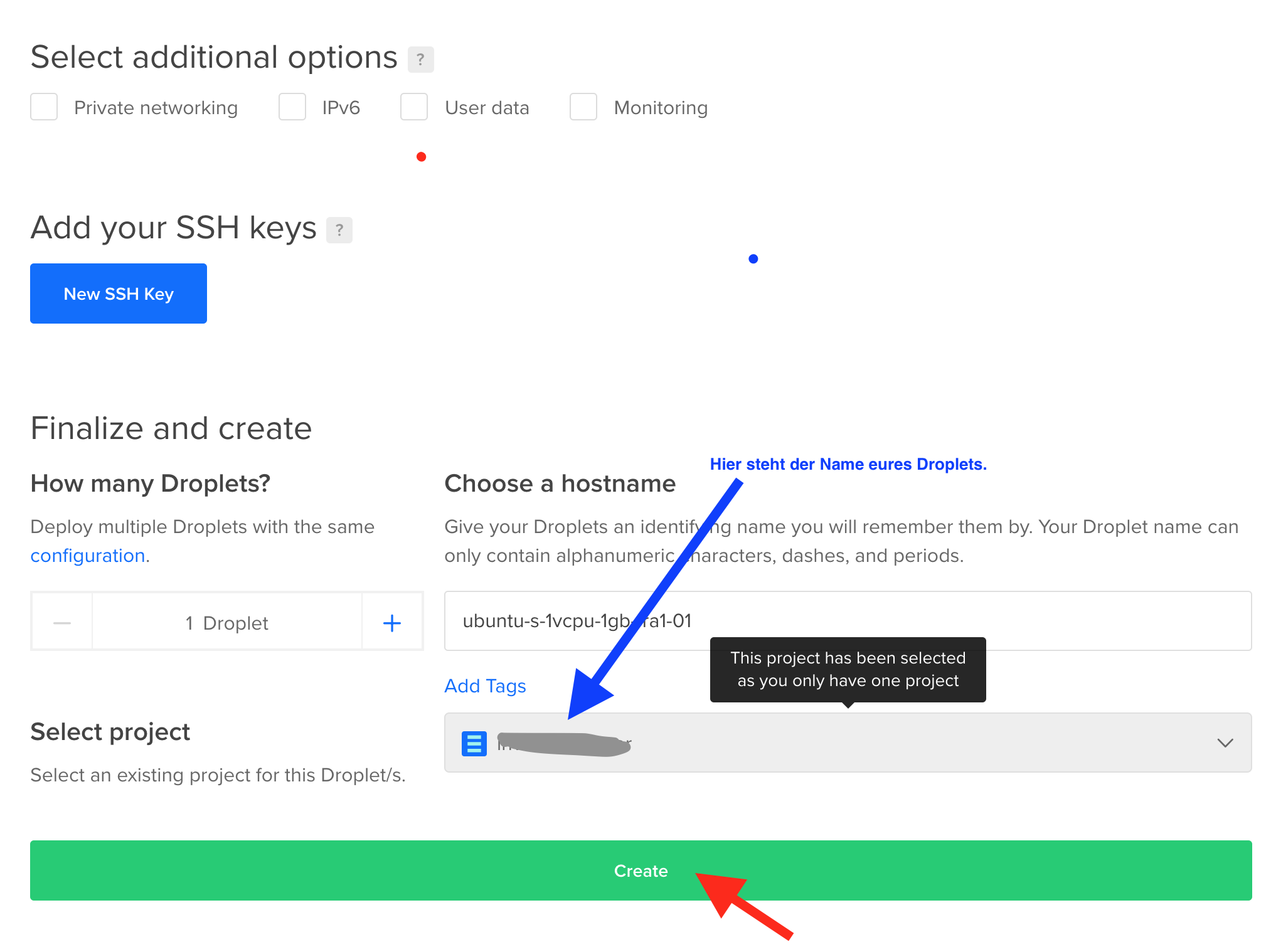
Abschließend noch einen Namen für das Droplet eingeben und dann bestätigen.
Nach kurzer Zeit erscheint euer Droplet. Ihr könnt direkt eure IP-Adresse sehen. Ein ssh-Passwort wurde euch an die E-Mail-Adresse geschickt, die ihr beim Anmelden hinterlegt habt.
Ihr könnt euch jetzt über euer terminal oder putty, wenn ihr auf Windows unterwegs seid so auf eurem System anmelden:
ssh root<eureIPAdresse>
Und nun das Passwort eingeben, dass euch per E-Mail zuschickt wurde. Fertig.
Patreon ist eine Plattform aus den USA, die es jedem ermöglicht Autoren, Künstler Musiker, Podcaster, YouTuber usw. seiner Wahl mit einer kleinen oder größere regelmäßigen spende zu versorgen.
Dadurch ist es eine gute Möglichkeit sich für alle Arten von Autoren sich ohne der Werbung zu unterwerfen zu finanzieren. Ich habe mir dort auch ein Profil für mein Projekt genughaben.de eingerichtet und habe seitdem dort auch keine automatische Werbung mehr. Sofern euch meine Seite gefällt und ihr mich unterstützen könnt, würde ich mich darüber freuen! Mein Profil findet ihr hier:
Seid ihr selbst Künstler, Autor, Musiker, Podcaster, YouTuber o.ä.? Dann meldet euch doch selbst auf Patreon an und schreibt euren Fans, dass sie euch darüber unterstützen könnt! Patreon bietet dazu viel und gute Unterstützung an, damit ihr damit auch Erfolg habt und ihr in Zukunft weniger von Werbung abhängig seid!
Viel Spaß und Erfolg mit eurem Projekt und danke für eure Unterstützung!
Immer wieder stehe ich vor Bücherregalen und würde zugern nach Stichworten suchen und dann entweder einen passenden Titel oder eine Empfehlung bekommen. Dazu fielen mir ein:
Foto machen unBücher in Buchläden (leichter) findend dann Suchanfragen (am liebsten per voice) auf das Bild schicken. Gefragte oder passende Bücher werden dann angezeigt.
App der Buchhandlung, die mit immer aktuellen Bildern der Bücherregale gefüllt werden. Nun kann ich als Besucher die Bücherregale durchsuchen – ggf. sogar von zuhause.
Da in einer Datenbank idealerweise auch Metadaten, Autorenname und Stichworte zum Inhalt liegen können diese für die Suche herangezogen werden.
Text in Bildern durchsuchen.
Manchmal möchte ich nach Begriffen in einem physischen Buch suchen. Cool fände ich da eine App, der ich meine Suchbegriffe eingeben kann. Mit meiner Telefonkamera filme ich dann über die Seiten und mir werden die passenden Begriffe gehighlighted. Manchmal netter als das Buch Zeile für Zeile mit den Augen durchzugehen.
Gestern war ich auf dem PyData Meetup in Hamburg bei Grunar + Jahr am Baumwall.
Ich werde her keine vollumfängliche Beschreibung, sondern nur jeweils das berichten, was ich am spannensten fand.
Es gab drei Vorträge:
1. Irina Vidal Migallón: Poking holes in your deep learning vision model.
Irina stellte Herausforderunge bei der Entwicklung von Bilderkennungsverfahren vor. Es ging dabei um Robustheit, die sie durch die vier Begriffe Evaluaton, Debugging, Interpretability und Adversarial* umriss. Irina arbeitete bereits im Bereich Medizin und Mobilität und wendete dort Bilderkennung an. In der Pause unterhielten wir uns u.a. über Ansätze “unbekannte” in Klassifikationen zu erkennen. Sie schlug Siemese Networks vor, die ich auch schon einmal ins Auge gefasst hatte – es ist aber immer gut das noch einmal von jemanden bestätigt zu bekommen 🙂
2. Matti Lyra: Research into production: automating travel bookings using current NLP research.
Matti erzählte über NLP zur Detektierung von Hotelbuchungen aus E-Mails. Ich fand den Vortrag technisch sehr spannend! Es ging darum aus E-Mails anfragen für Hotels zu extrahieren. Für mich nicht so relevant – da ich lieber ein Formular verwende, dass für mich gleichzeitig wie eine Checkliste fungiert und für mich so sicher stellt, dass ich nichts wichtiges vergessen habe. Für einen vielreisenden Businessman aber vielleicht genau das richtige!
Christopher Werner: Prediction of Status Changes in Software Tests.
Auch ein spannender Vortrag. Technisch betrachtet. Es ging darum zu erkennen, ob be einen Commit der Status eines Tests sich ändert. Hier war allerdings der Use Case für mich nicht wirklich nachvollziehbar. Problem des Kunden war: die Tests brauchen 1,5 Tage bis sie durchlaufen. Fair enough. Aber warum dann nicht die Anwendung in Services mit jeweils kleineren Testsuits unterteilen? Und wenn das keine Option ist: warum nicht an Teilen des Codes entwicklen und nur die dafür relevanten Suites ausführen? Immer noch sicherer als die Endgenauigkeit von circa 80% des vorgestellten Modells: denn ein mit 20%iger Wahrscheinlichkeit fehlerhaftes Update würde ich nicht deployen wollen…
Key Takeaways waren für mich:
automatisiere deine Workflow so gut wie möglich
Evaluiere und visualisiere dein Training (z.B. mit Tensorboard) und die Modellperformance
verwende für die Modell-Validierung das Gerät, die Umgebung und Kennzahlen (z.B. precision oder recall), die später beim Deployment verwendet werden und für den Anwendungsfall am relevantesten sind.
schauen worauf dein Modell schaut: Stichwort “Deconvolution” – erkennt das Modell wirklich das, was wir wollen und vor allem aus erwarteten Gründen? Wird der Wolf im Bild erkannt oder nur der Schnee im Hintergrund? Ein Tool dafür ist Lime. Dazu gibt es dort ein cooles Video. Ein gutes Paper dazu ist: Why should I trust you?
reichere deinen Datensatz neben augmentierung durch adverserial samples an (siehe Explaining and Harnessing Adversarial Examples von Goodfellow 2014). Es werden “zufällige Muster” deinen Trainingsbildern hinzugefügt, die für die Erkennung anderer Bildklassen optimiert sind. Dein Modell muss daher dann lernen, warauf es in den Trainingsbildern “wirklich ankommt”. Dafür hilft das Tool cleverhans.
Ein für das Trainieren von Modellen für autonomes Fahren oft verwendeter Datensatz ist der City Scape Dataset.
Ein spannedes System zum Ausprobieren der richtigen Hyperparameter ist hyperband. Hier arbeitet im Hintergrund ein Multi-armed bandit, um nach und nach für definierte Rampen von Hyperparametern die optimale Kombination zu finden.
Selbst sprechen:
Auch interessant fand ich:
Wer will kann sich dort jederzeit mit einem Vortragsthema melden und bei einer neuen Veranstaltung sprechen.
Auch kürzere Talks (bis 5min) sind am Ende in der Section “Lightning Talks” immer möglich.
Erstellt lokal einen neuen Branch mit dem Namen <name-des-remote-branches>, der auf dem Stand des gleichnamigen remote branches ist. Dieser neue branch ist auch direkt für weitere commits oder pulls von remote bereit.
Rückgängig machen des letzten Commits [Änderungen behalten]:
git reset --soft HEAD~1
Dabei werden die Changes für den letzten commit gelöscht, sondern verbleiben nach Ausführen des Befehlts als uncommitete Veränderungen, die nun weiter verändert oder ersetzt werden können.
Rückgängig machen des letzten Commits [Änderungen löschen]:
git reset --hard HEAD~1
Dieser Befehl macht den letzten commit rückgängig und löscht die damit verbundenen Änderungen.
Rückgängig machen mehrerer commits.
Ihr wollt mehrere commits rückgängig machen. Ihr kennt die genaue Anzahl? Und sie ist x. Dann verwendet dafür:
git reset --soft HEAD~x
git reset --hard HEAD~x
Ihr kennt sie nicht und habt keine Lust zu zählen. Dan schaut via git log den Hash des letzten Commits nach: z.B. 0bc1yz und gebt ein:
git reset --soft 0bc1yz
git reset --hard 0bc1yz
Zeige commits aus einem Branch, die nicht in einem anderen Branch sind.
Der folgende Befehl zeigt dir, welche commits zwar bereits im <feature_branch>, aber noch nicht im <other_branch> sind:
Das ist ein Vector Zeichenprogramm. So ähnlich wie Inkscape. Da Inkscape aber auf Mac einfach überhaupt nicht ordentlich funktioniert, habe ich mir vor circa eine Woche die Trail des Affinity Designers geholt und bin mir ziemlich sicher, dass ich mir das Programm kaufen werden in drei Tagen, wenn die Trail ausläuft. Ich verwende das Programm zusammen mit dem Intuos 4 Medium. Wenn ich etwas mehr Geld hätte, würde ich mir aber das Intuos Pro Medium oder sogar ein Cintiq 13HD holen. Das mache ich sobald sich bewährt hat, dass ich meine Artikel für genughaben, permakultur-praktisch und genugschlafen regelmäßig illustriere, wie ich es z.B. hier erstmals getan habe. Absolut genial, gute Shortcut-Funktionen für das Programm, etwas weniger für mein, besser für die teureren Grafiktablets. Vieleicht probiert ihr es ja auch mal aus.
Was ich lese.
Ich versuche mir jetzt jeden Vormittag 1-2 Stunden Zeit zum Lesen zu nehmen. Gestern war das:
The Marriage Descision: Everything forever or Nothing Ever Again auf Tim Urbans Blog waitbutwhy. Tim Urban untersucht die Art und Weise wie man sich dafür oder dagegen entscheiden kann.
Heute habe ich The Age of the Essay von Paul Graham gelesen. Wieder. Er kommt darauf, das moderne Essays sich an die Streitschriften anlehnen, die man in Gerichtssälen benötigt und daher zu wenig mit Wahrheitsfindung zu tun haben, das will er anders machen. Er will, dass seine Essays im Sinne Montaignes der Wahrheitsfindung dienen. Er notiert alles ihn überraschende und denkt dann schreibend darüber nach, diskutiert die Ergebnisse mit Freunden und schreibt dort um, wo es zu langweilig oder nicht überzeugend ist. Er beginnt anders als mit modernen Texten nicht mit einer initialen These, das ist aus seiner Sicht Sophismus. Ich kann ihm da nur zustimmen. Hier ein paar Zitate aus dem Text.
Zitat: Whatever you study, include history– but social and economic history, not political history. History seems to me so important that it’s misleading to treat it as a mere field of study. Another way to describe it is all the data we have so far.
Zitat: Swords evolved during the Bronze Age out of daggers, which (like their flint predecessors) had a hilt separate from the blade. Because swords are longer the hilts kept breaking off. But it took five hundred years before someone thought of casting hilt and blade as one piece.
Zitat. Über Ungehorsam: Above all, make a habit of paying attention to things you’re not supposed to, either because they’re “inappropriate,” or not important, or not what you’re supposed to be working on. If you’re curious about something, trust your instincts. Follow the threads that attract your attention.
Zitat: Gradualness is very powerful. And that power can be used for constructive purposes too: … you can trick yourself into creating something so grand that you would never have dared to plan such a thing. Indeed, this is just how most good software gets created. … Hence the next leap: could you do the same thing in painting, or in a novel?
Zitat: If there’s one piece of advice I would give about writing essays, it would be: don’t do as you’re told. Don’t believe what you’re supposed to. Don’t write the essay readers expect; one learns nothing from what one expects. And don’t write the way they taught you to in school.
in dieser Serie von Artikeln will euch ein ganzheitliches Verständnis über Machine Learning vermitteln. Wir werden eine Reihe von Algorithmen kennenlernen, wir werden uns dazu verschiedene Typen von Lernverfahren anschauen. Darunter sind sog. überwachte Lernverfahren wie Regression, Klassifikation (z.B. mit Support Vector Machines) sowie unüberwachte Lernverfahren wie Clustering (hierarchische und nicht-hierarchische Verfahren wie z.B. k-Means ) und schließlich werden wir zu Deep-Learning mit neuronalen Netzwerken übergehen und uns Bilderkennung und Reinforcement-Learning anschauen. Euch sagen viele dieser Begriffe nichts oder ihr habt nur eine vage Vorstellung davon? Dann ist diese Artikelserie für euch richtig!
Wir werden uns zu jedem Verfahren die zugrunde liegende Intuition und Theorie aus der Vogelperspektive anschauen, Anwendungen mit scikit-learn in Python kennenlernen. Dafür werden wir anhand realer Daten sehen, was die Verfahren von uns als Input erwarten, was wir als Output erhalten können, und wie wir diesen interpretieren können.
Schließlich wollen wir uns aber auch die genaue Funktionalität anschauen, indem wir die zugrundeliegende Mathematik nachvollziehen und noch tiefer eintauchen. Dafür werden wir die Verfahren in einfacher Weise selbst programmieren. Das wird euch letztlich helfen, die Verfahren wirklich zu verstehen, was euch in Zukunft helfen wird, wenn ihr die Verfahren auf neue Problemstellungen anwenden werdet.
Voraussetzungen sind Grundkenntnisse in Python 3. Es schadet nicht, wenn ihr euch etwas in Wahrscheinlichkeitsrechnung und Statistik auskennt. Es ist aber keine zwingende Voraussetzung. Ich will versuchen es einfach zu halten.
Was ist Machine Learning? Ein erstes Beispiel.
Machine Learning ist nicht alt. Die Forschungsgeschichte beginnt in etwa in den 1950er Jahren. Machine Learning ist die Wissenschaft oder Kunst, Maschinen (bzw. Computer) so zu programmieren, dass diese selbstständig aus Daten lernen können.
Arthur Samuel (Quelle: Wikipedia)
Arthur Samuel definierte etwas allgemeiner im Jahre 1959: Machine Learning ist die Erforschung von Methoden, Maschinen die Fähigkeit zu geben zu lernen, ohne sie explizit zu programmieren.
Eine quantitativere Definition ist die folgende: Eine Machine lernt aus einer Menge Daten D, in einer bestimmten Aufgabe A in Bezug auf ein Leistungsmaß L besser zu werden, wenn die Leistung in Bezug auf A gemessen in L mit der Menge D zunimmt.
Letztlich geht es darum, sich das Leben einfacher zu machen und Wissen nicht explizit in Form von Regeln programmieren zu mussen, sondern einer Maschine ein Verfahren zu geben, mit dem sie selbstständig lernt. Ein Beispiel ist der Spamfilter. Er erkennt anhand von Beispielen für Spam und Nicht-Spam (“Ham”) neuen Spam und Ham. Weil er mit Beispielen arbeitet, die ihm sagen, wonach er suchen soll, spricht man dabei von einem sog. überwachten Lernverfahren. Eine sehr simple Methode, Spam zu erkennen wäre folgende: jede neue E-Mail wird mit einer Liste von Spam-E-Mails vergleichen, von denen der Spamfilter bereits weiß, dass sie Spam sind. Es muss dann aber nur ein einzelnes Wort, ja nur ein einzlener Buchstabe in einer neuen Spam-E-Mail anders sein als in einer der bereits bekannten Spam-E-Mail und der Spamfilter würde diese E-Mail nicht mehr als Spam erkennen. Ihr könnte euch vorstellen, dass durch Austauschen oder Hinzufügen von Zeichen in bereits bekannte Spam-E-Mails unbegrenzt viele neue Varianten von Spam enstehen könnten. Es ist also kein sinnvolles Verfahren, Spam-E-Mails durch “Auswendiglernen” bzw. durch von Hand programmierte Regeln zu erkennen. Besser wäre es, wir hätten ein Verfahren, dass Spam-E-Mails automatisch, möglichst zuverlässig detektiert, ohne “echte” E-Mails auszusortieren. Wir brauchen ein echtes Vorhersageverfahren.
Hier kommt Machine Learning ins Spiel. Eine Möglichkeit wäre nun, dass ein Verfahren lernt, welche Worte häufiger in Spam und welche häufiger in Ham vorkommen. Ein Machine-Learning-Verfahren könnte nun die Wahrscheinlichkeit, ob eine Mail Spam oder Ham ist aus der Anzahl Worte ableiten, die eher in Spam oder eher in Ham auftreten.
Eine der ersten hierfür eingesetzten Methoden war der sogenannte Naive Bayes Filter. Es handet sich dabei um ein überwachtes Lernverfahren und genauer eine sog. Klassifizierungsmethode. Sie klassifiziert E-Mails entweder als Spam oder Ham.
Zu Anfang weiß der Naive-Bayes-Filter nichts. Er braucht zunächst Daten D. Diese bekommt er von uns, die wir E-Mails lesen und als Spam markieren. Immer wenn du oder ich eine E-Mail als Spam markieren, kann der Spamfilter lernen, dass die Worte aus der Spam-E-Mail für Spam typisch sind. Tritt nun in vielen Spam-E-Mails immer wieder das Wort “Viagra” auf, so werden diese in Zukunft herausgefiltert. Der Naive Bayes Filter wird mit den von uns gelieferten Daten D, in seiner Aufgabe A Spam zu erkennen in puncto Leistungsmaß “Anteil richtig erkannter Spam-E-Mails” L mit zunehmender Menge Daten D besser.
Wir werden in den nächsten Kapiteln weitere Aufgaben und weitere Methoden kennenlernen.
Wir leben im goldenen Zeitalter des Machine Learning!
Wir leben in einer aufregenden Zeit! Ihr könnt heute das Machine Learning Verfahren eurer Wahl auf 100.000 Euro teurer Hardware bei z.B. Amazon AWS, Googles Cloud oder Microsoft Azure oder vielen anderen Anbeitern auf Terrabytes von Daten anwenden und Modelle erhalten – zum Spaß, für eure Softwareprojekte oder eure Businessidee. Und das Ganze für wenige Euros pro Stunde. Gleichzeitig sind über Programmiersprachen wie Python und Module wie scikit-learn Machine-Learning-Verfahren auch für wenig erfahrene Entwickler verfügbar. Viele Verfahren lassen sich auch ohne Verständnis ihrer genauen Funktionsweise sofort anwenden. Wer es etwas genauer Wissen will und bessere Ergebnisse erzielen will und erfahren will, für welches Problem, welches Verfahren am besten geeignet ist, für den ist diese Aritkelserie!
Im nächsten Teil werden wir uns Machine Learning noch etwas genauer aus der Vogelperspektive anschauen und lernen, welche Arten von Verfahren es gibt. Im übernächsten Artikel werden wir bereits eine erste Aufgabe und eine praktische Lösung dafür kennenlernen.
Ich rege mich im Alltag immer wieder über aus meiner Sicht technische Probleme auf, die einfach nicht gelöst werden. Das meiste davon ist nicht Kriegsentscheidend. Wenn man aber bedenkt, dass unsere Gesellschaft eben an vielen Stellen durch inkrementelle Beschleunigung besser geworden ist, sind sie aber dennoch eine Diskussion wert. Ich werde immer wieder mal eine Sache in den Raum stellen, die mir auf den Geist geht. Und bin auf eure Meinungen bzw. Kommentare dazu gespannt.
Heute: Google Maps.
1. Man bekommt vom Google Assistant auch für Kontakte für die man die Adresse hinterlegt auf Anfrage keine Route. Frage ich etwa:
* Ok Google.
* Zeige mir den kürzesten Weg zu bekomme ich eine Google Suche als Ergebnis.
What? Das kann doch wohl nun echt nicht so schwer sein, Dr. Google. Löst das bitte mal. Nicht immer nur von Innovationgeschwindigkeit reden, sondern auch mal machen!
Nicht falsch verstehen, liebe Google, ich finde euch klasse, aber manche Funktionen könntet ihr einfach echt noch verbessern! Meiner Meinung nach könnte da helfen euer Image als Runaways in der Techsphäre zu stabilisieren!
2. Ich reise beruflich häufiger. In den jeweiligen Städten bin ich aber wiederholt an denselben Orten. Dennoch ist die Angabe “Arbeit” immer die gleich für einen meiner Einsatzorte in Hamburg. Nie aber in dem für Frankfurt, Desden oder wo auch immer. Gleichzeitig könnten die letzten Suche sich am jeweiligen Aufenthaltsort orientieren. Wenn ich eben in Frankfurt bin, dann interessieren mich meine Ortssuchen aus Hamburg eher weniger. Richtig genial wären ja Ortsprofile, die man über einen Button und dann ein Dropdown auswählen könnte.
Zusammengenommen würde mir beides pro Monat bestimmt 5 Minuten sparen. Und noch mehr Nerven, denn ich ärgere mich über beides sicher länger als die eingesparte Zeit. Auf 1.000.000 Menschen, die das auch interessieren könnte wären das pro Monat dann also 1041 Tage. Das ist schon ne Menge Holz. Würde sich also schon lohnen das einzubauen.
Danke und beste Grüße
Frank
Manage Cookie Consent
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.